
 一对多、多对多关系的表设计
一对多、多对多关系的表设计# 一对多和多对多的表的设计
上节我们学了一对一,这节继续来学习一对多和多对多。
一对多关系在生活中随处可见:
一个作者可以写多篇文章,而每篇文章只属于一个作者。
一个订单有多个商品,而商品只属于一个订单。
一个部门有多个员工,员工只属于一个部门。
多对多的关系也是随处可见:
一篇文章可以有多个标签,一个标签可以多篇文章都有。
一个学生可以选修多门课程,一门课程可以被多个学生选修。
一个用户可以有多个角色,一个角色可能多个用户都有。
那在数据库里如何建模这种关系呢?
我们分别来看一下:
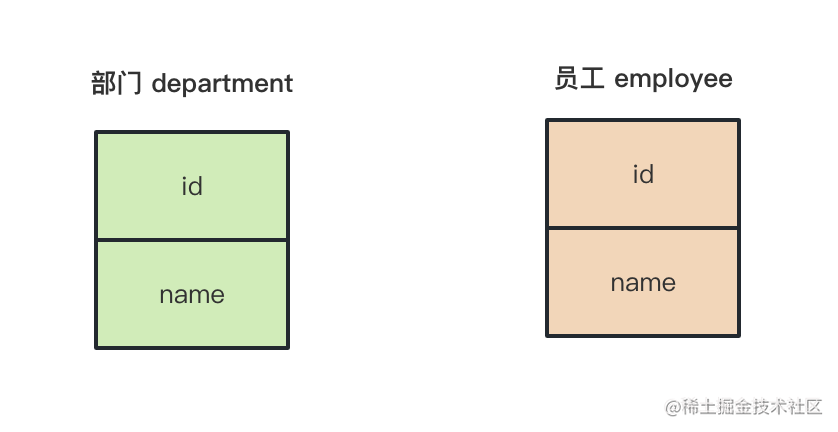
# 一对多的关系,比如一个部门有多个员工。
我们会有一个部门表和一个员工表:
在员工表添加外键 department_id 来表明这种多对一关系:
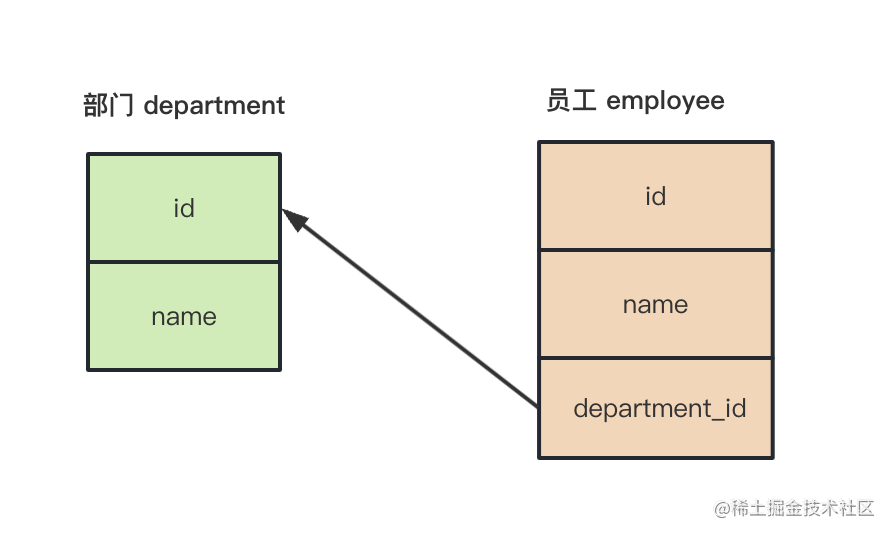
其实和一对一关系的数据表设计是一样的。
我们添加这两个表。
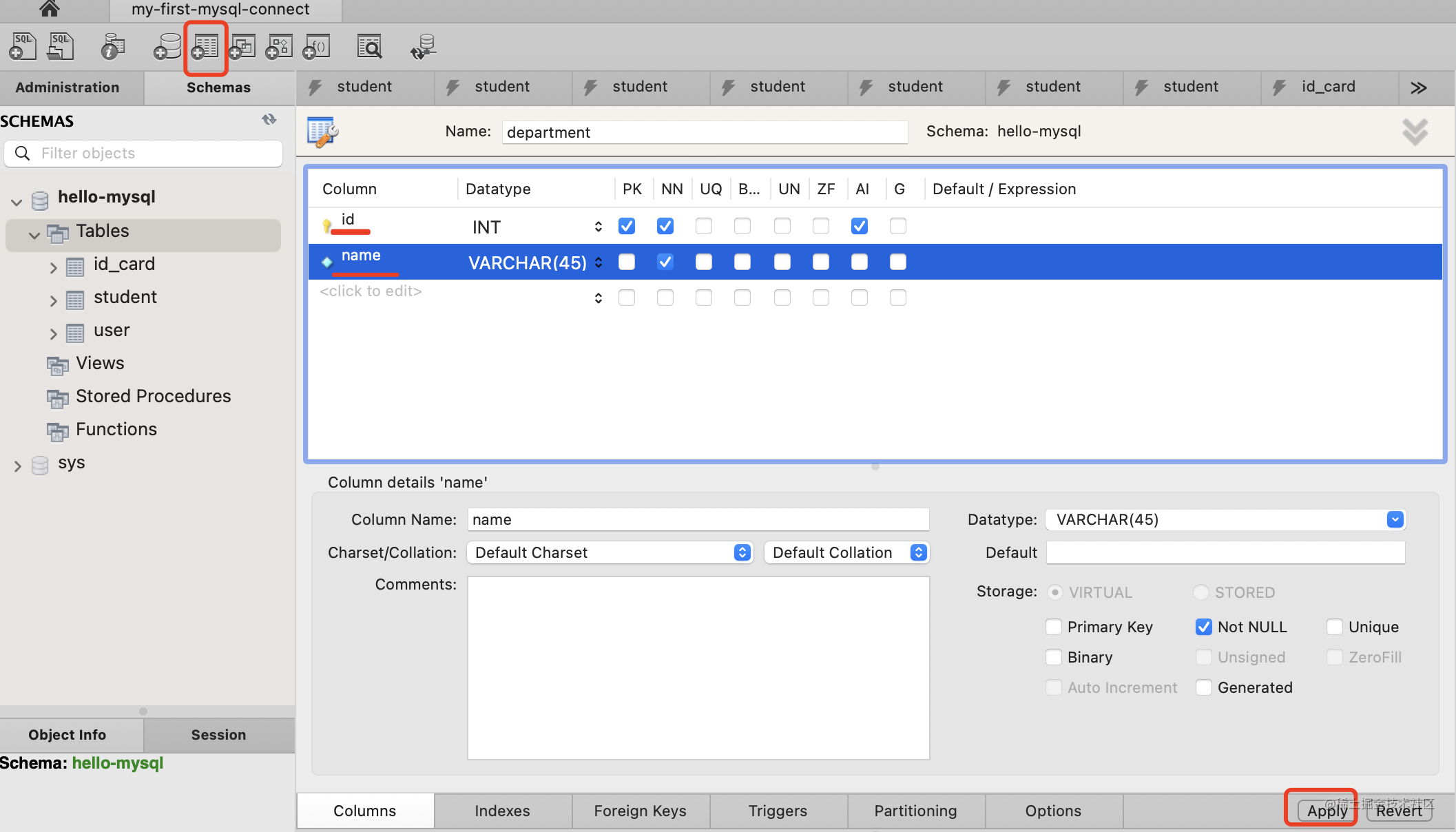
分别指定 id 是 INT,约束为 primary key、not null、 auto increment 。
name 是 VARCHAR(45),约束为 not null。
点击 apply。
建表 sql 如下:
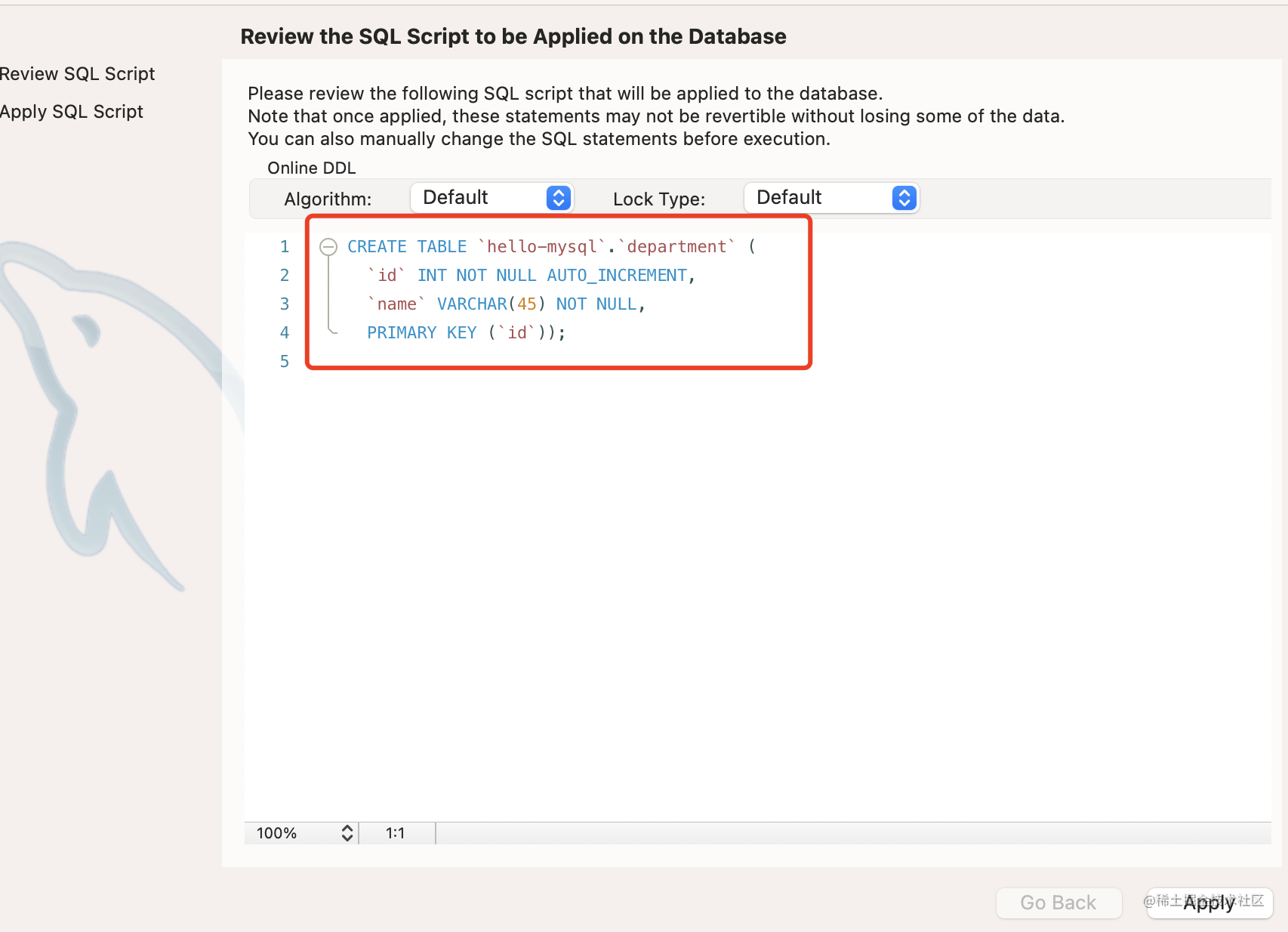
同样的方式创建 employee 表:
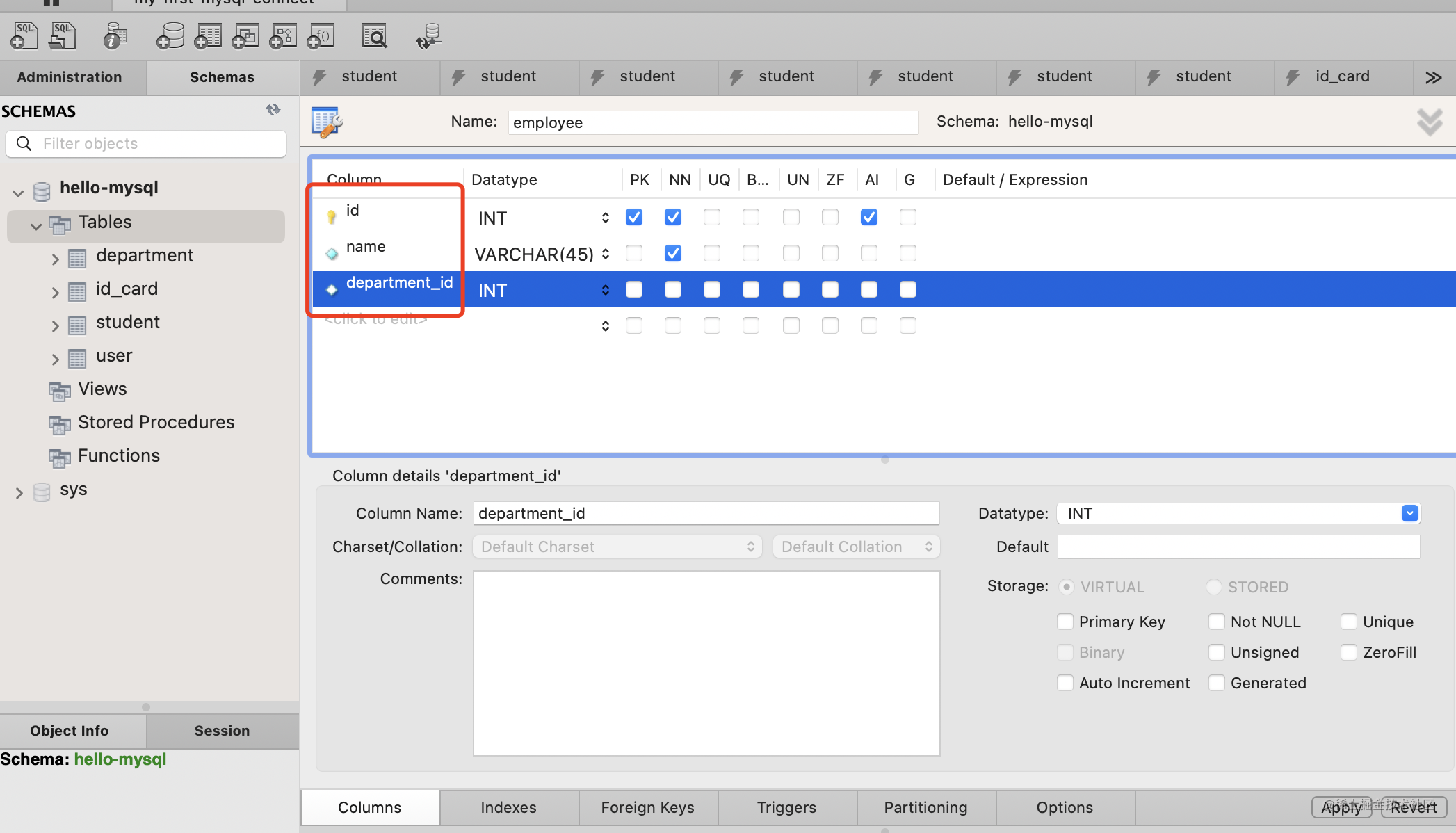
添加 id、name、department_id 这 3 列。
然后添加一个外键约束,department_id 列引用 department 的 id 列。
设置级联删除和更新为 SET NULL。
因为部门没了员工不一定也没了,可能还会分配到别的部门。
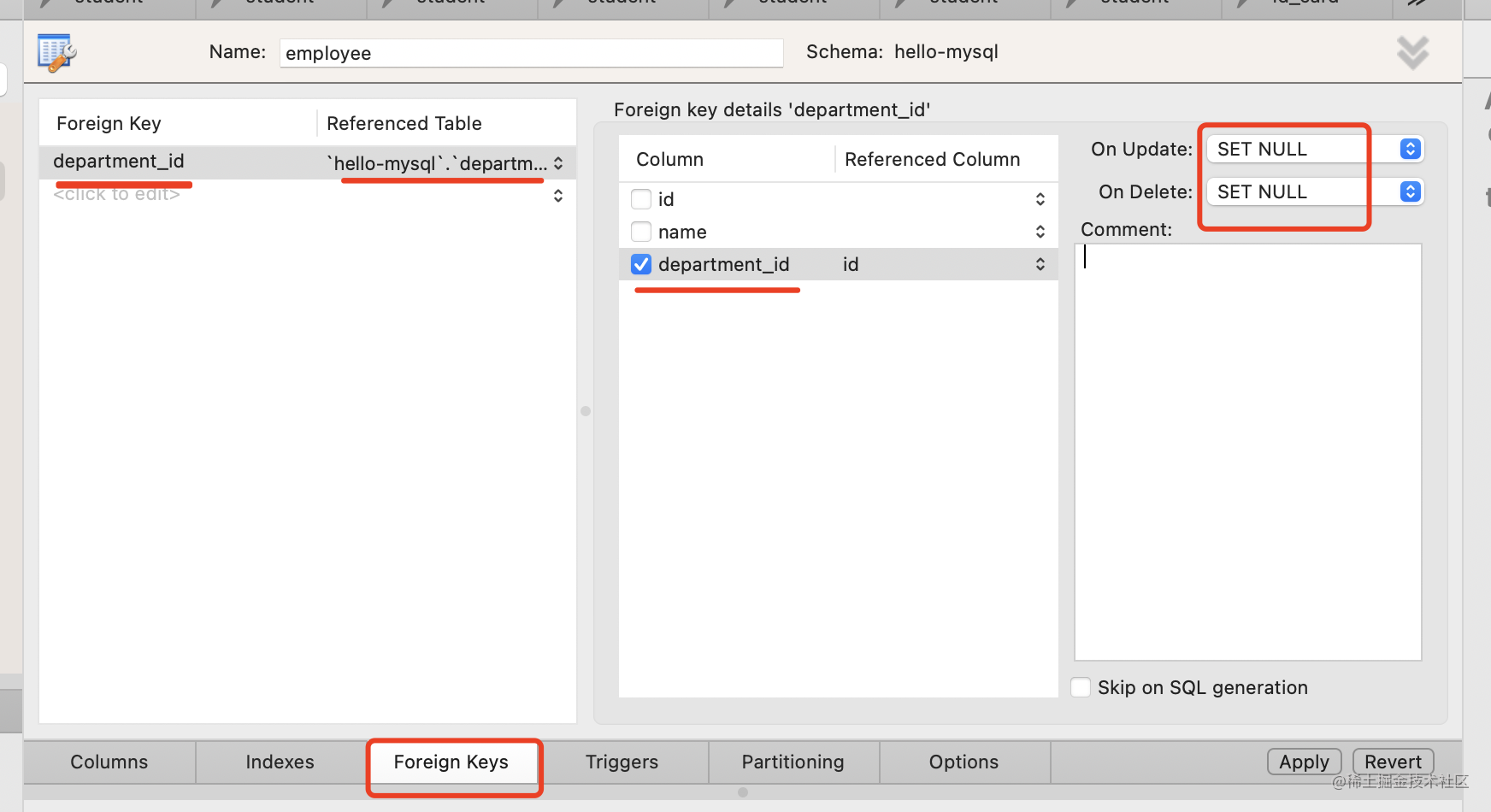
点击 apply 就创建成功了。
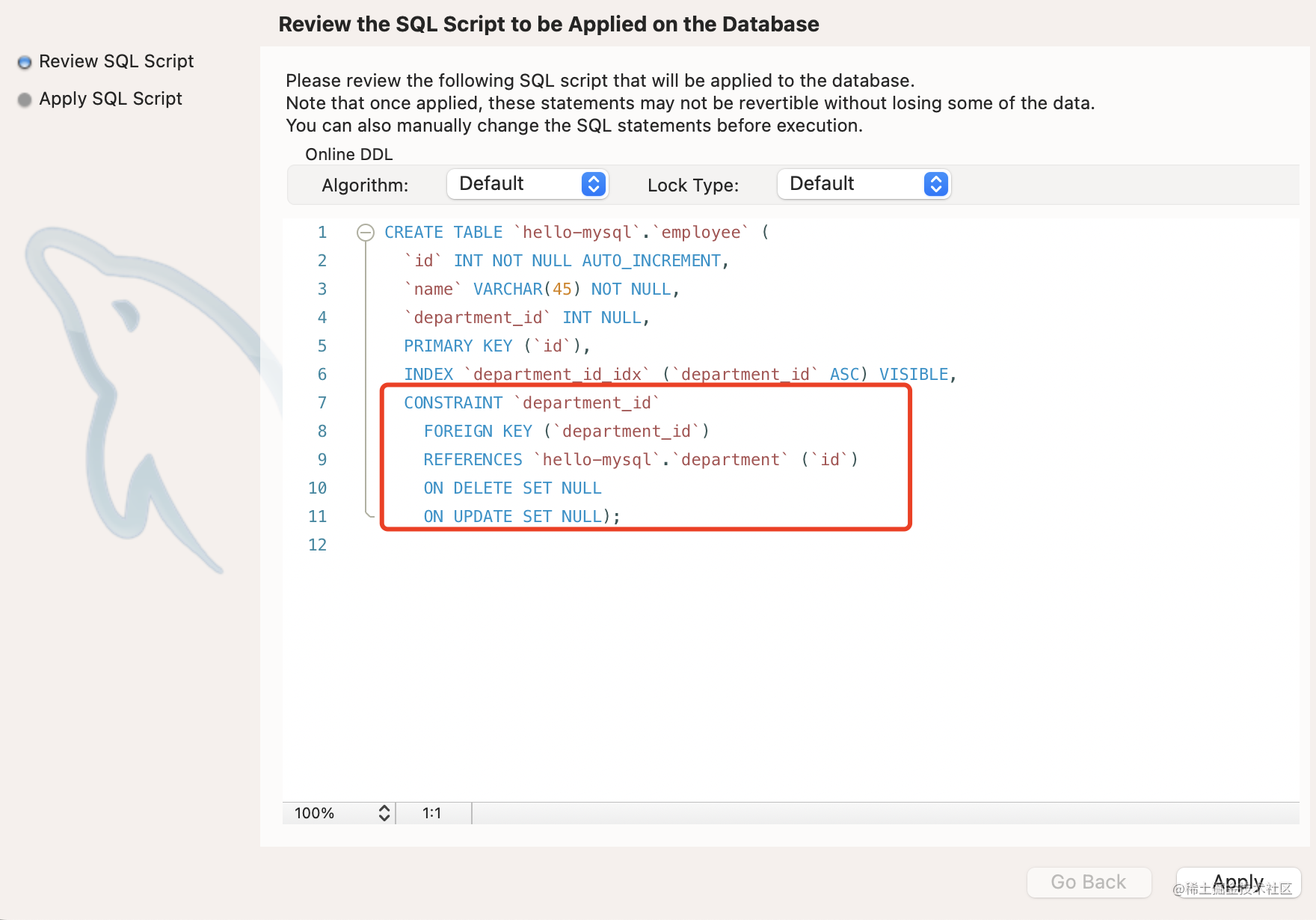
sql 的最后这段,就是创建了一个外键约束,department_id 引用了 department 表的 id,设置级联删除和更新方式为 SET NULL。
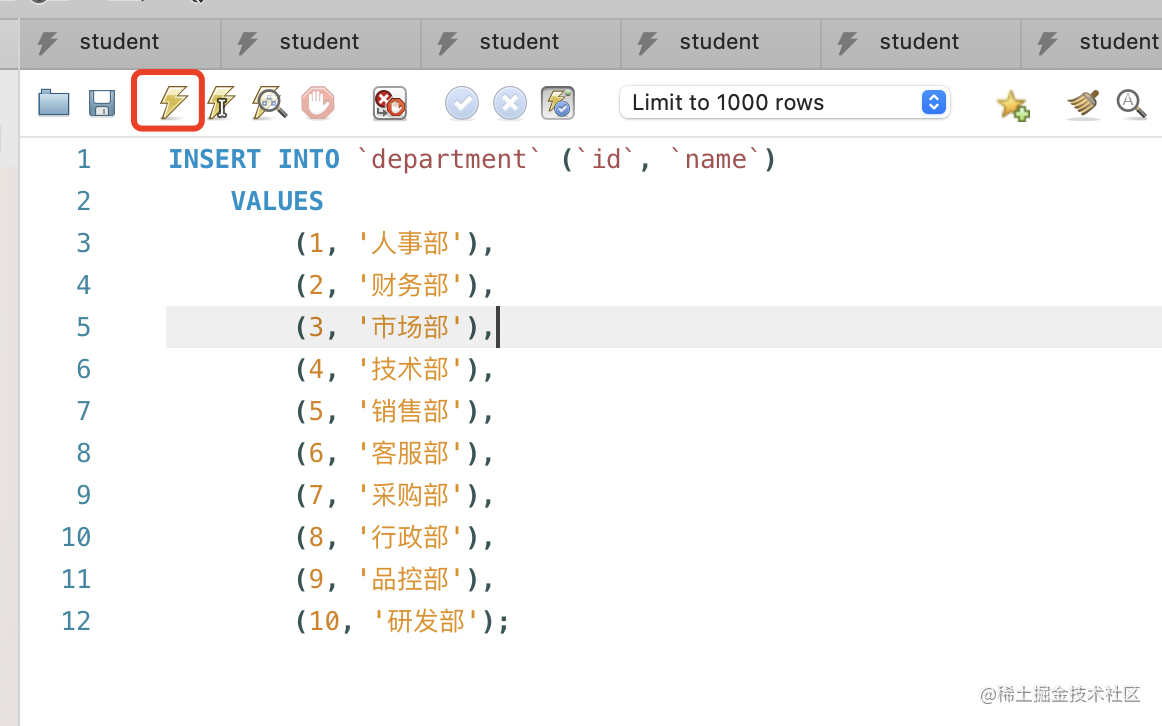
我们往部门表插入几条数据:
INSERT INTO `department` (`id`, `name`)
VALUES
(1, '人事部'),
(2, '财务部'),
(3, '市场部'),
(4, '技术部'),
(5, '销售部'),
(6, '客服部'),
(7, '采购部'),
(8, '行政部'),
(9, '品控部'),
(10, '研发部');
2
3
4
5
6
7
8
9
10
11
12
查询下:
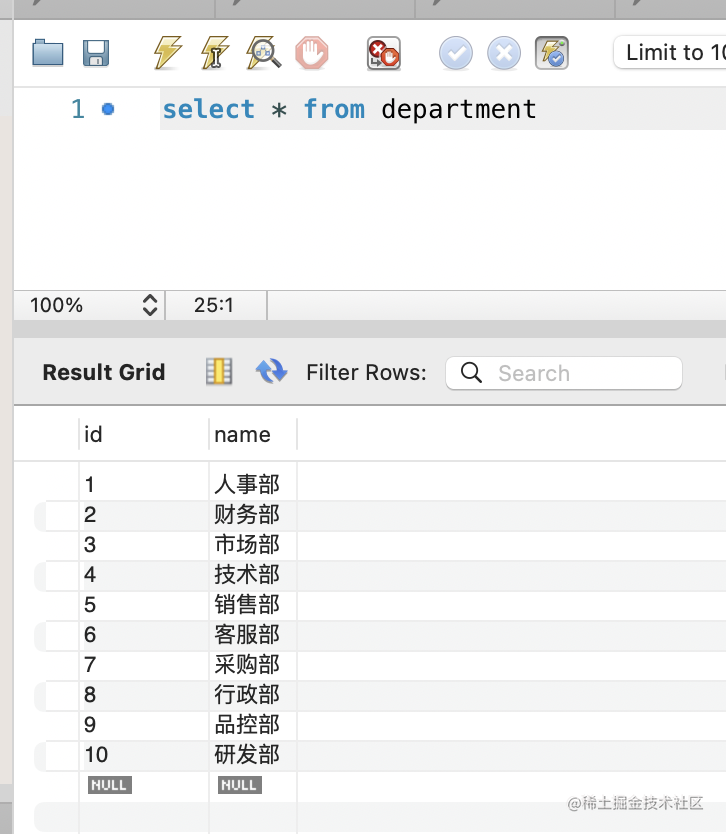
插入成功了。
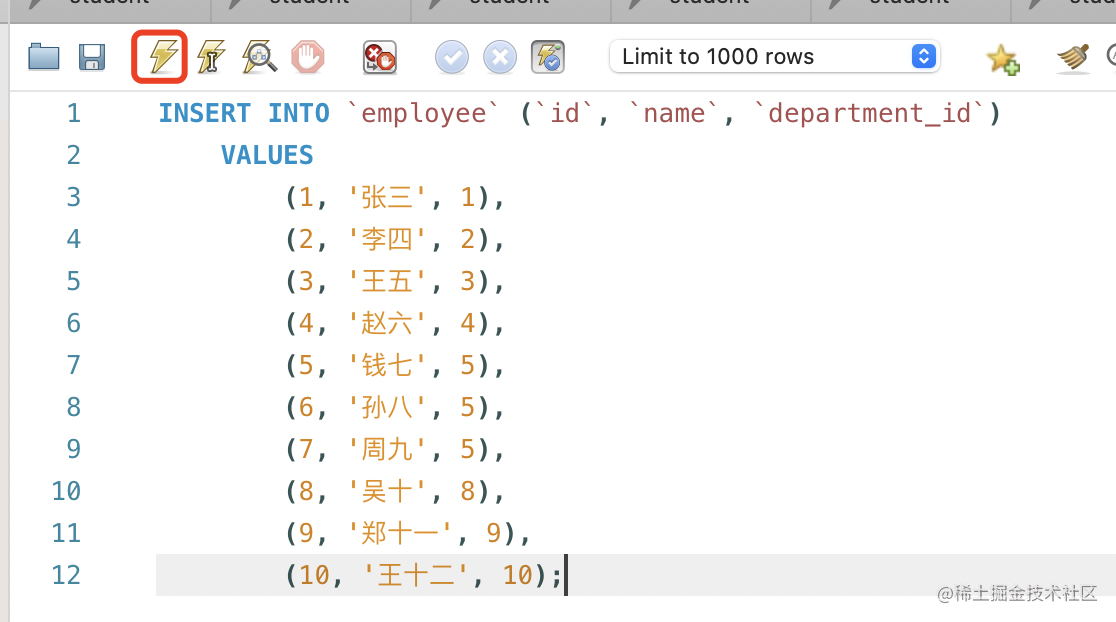
再往员工表里插入几条数据:
INSERT INTO `employee` (`id`, `name`, `department_id`)
VALUES
(1, '张三', 1),
(2, '李四', 2),
(3, '王五', 3),
(4, '赵六', 4),
(5, '钱七', 5),
(6, '孙八', 5),
(7, '周九', 5),
(8, '吴十', 8),
(9, '郑十一', 9),
(10, '王十二', 10);
2
3
4
5
6
7
8
9
10
11
12
查询下:
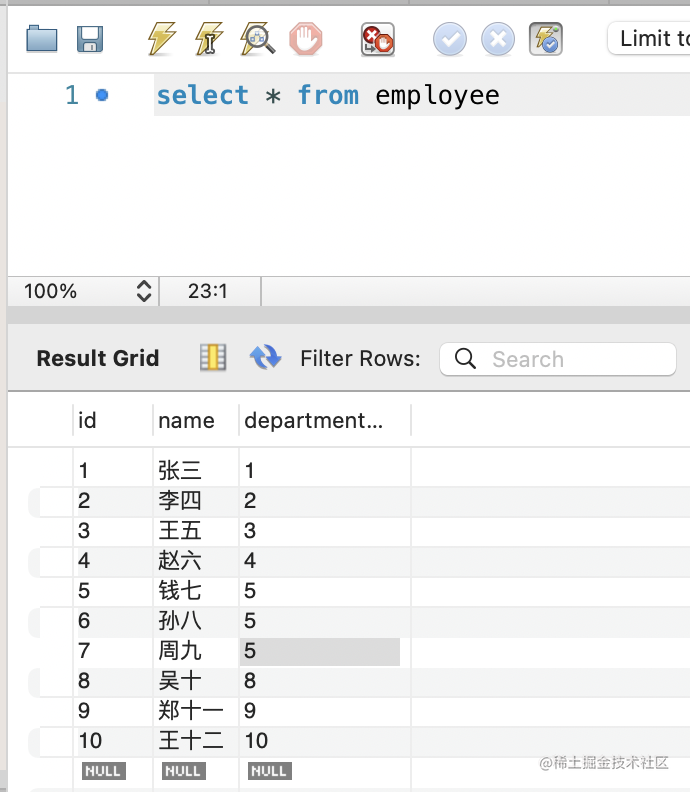
同样插入成功了。
我们通过 JOIN ON 关联查询下 id 为 5 的部门的所有员工:
select * from department
join employee on department.id = employee.department_id
where department.id = 5
2
3
可以看到,正确查找出了销售部的 3 个员工:
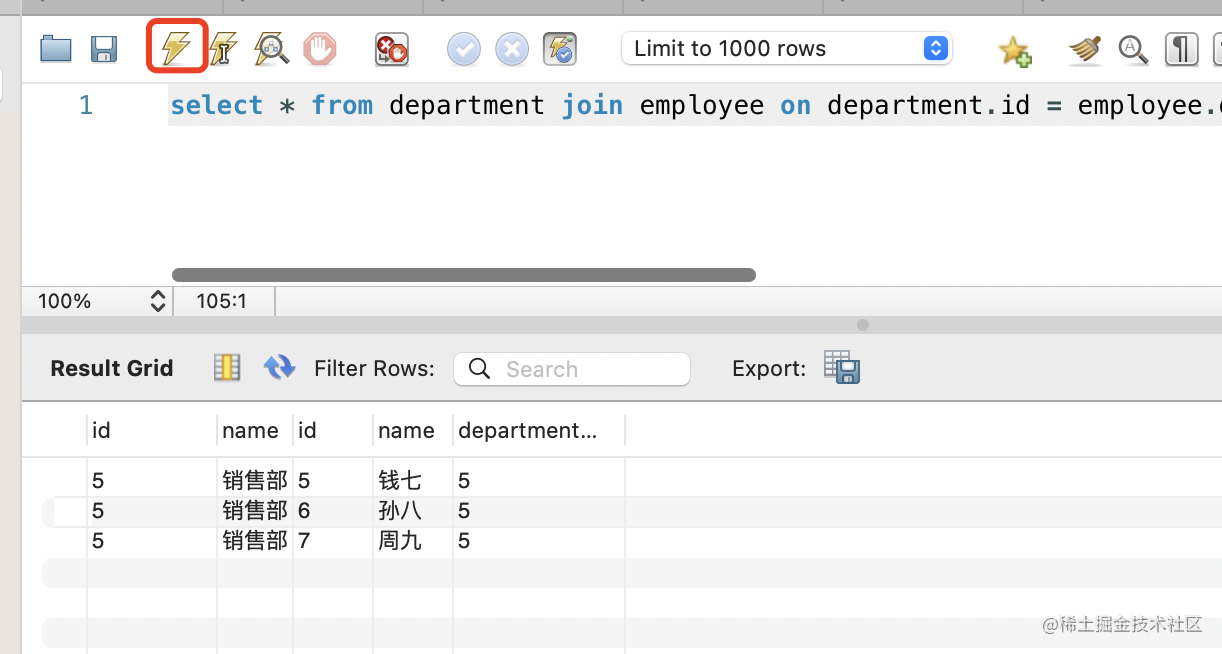
JOIN ON 默认是 INNER JOIN。
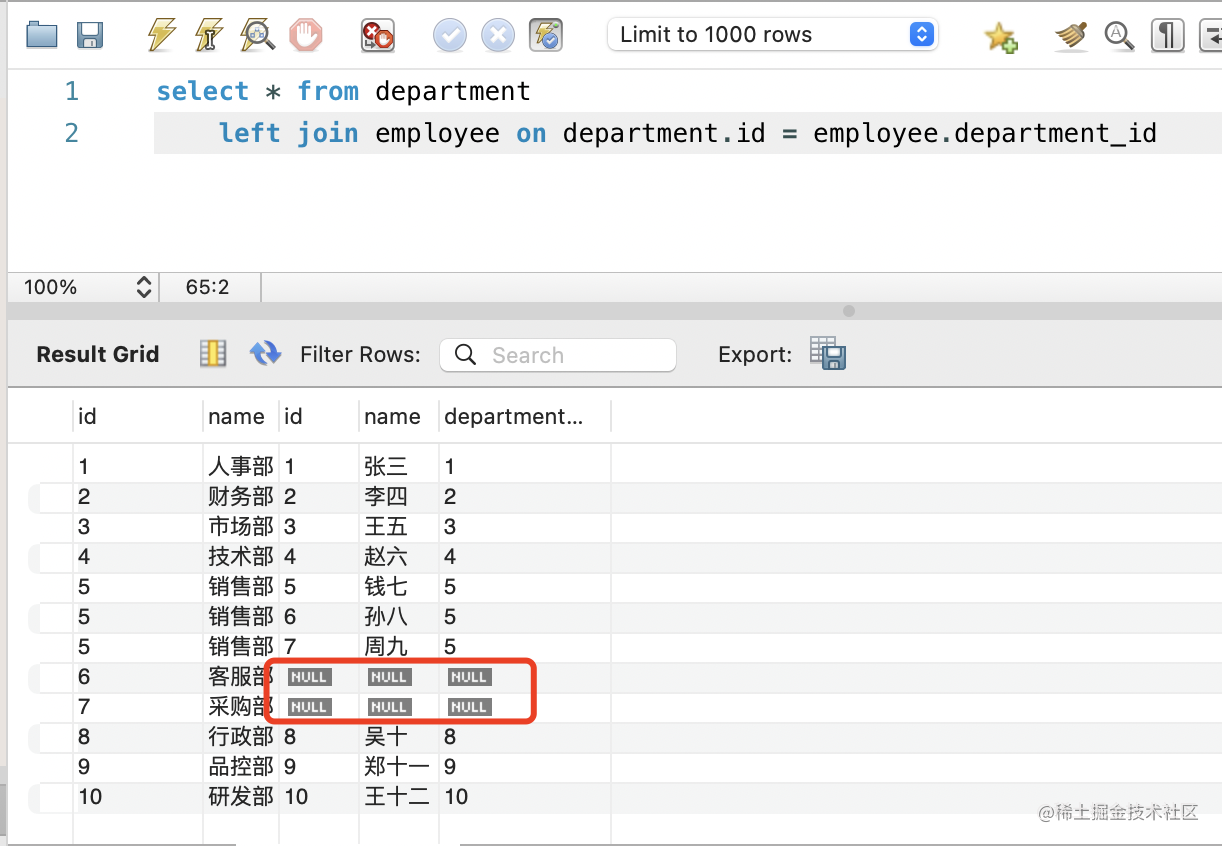
我们再来试试 LEFT JOIN 和 RIGHT JOIN:
select * from department
left join employee on department.id = employee.department_id
2
from 后的是左表,可以看到两个还没有员工的部门也显示在了结果里:
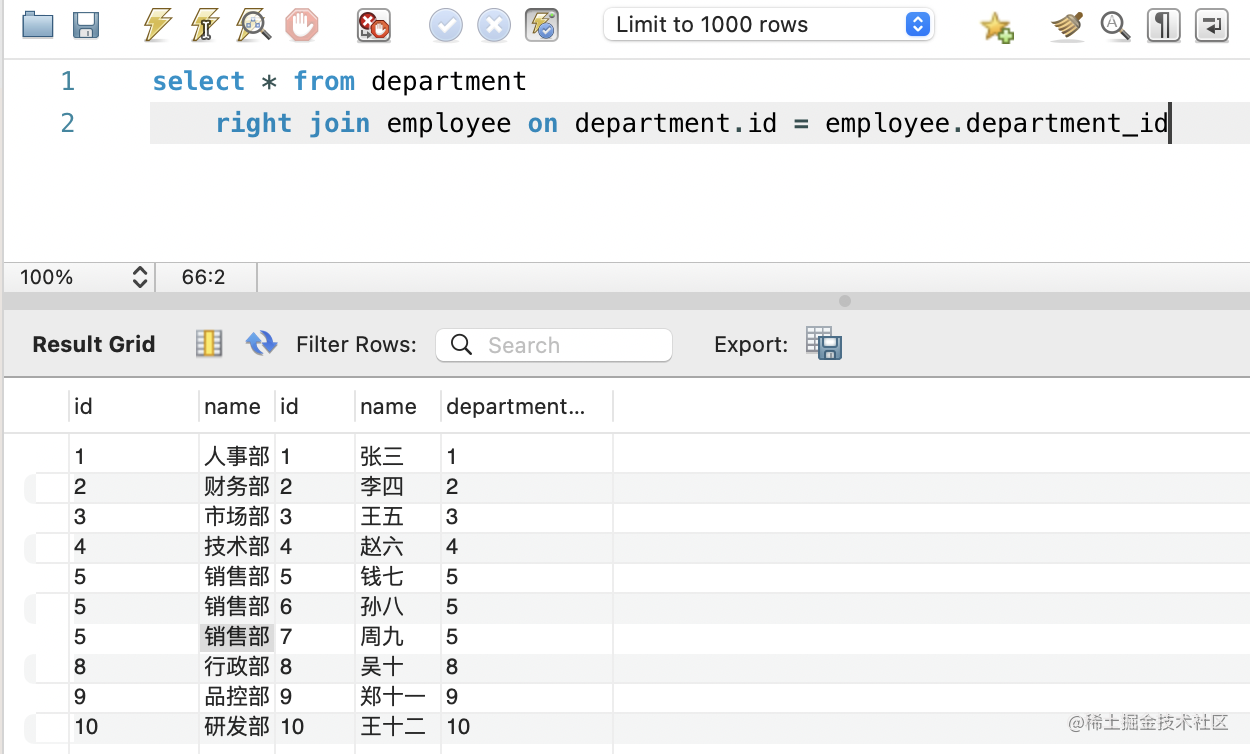
然后是 RIGHT JOIN:
select * from department
right join employee on department.id = employee.department_id
2
因为所有的员工都是有部门的,所以和 inner join 结果一样:
然后把 id 为 5 的部门删掉:
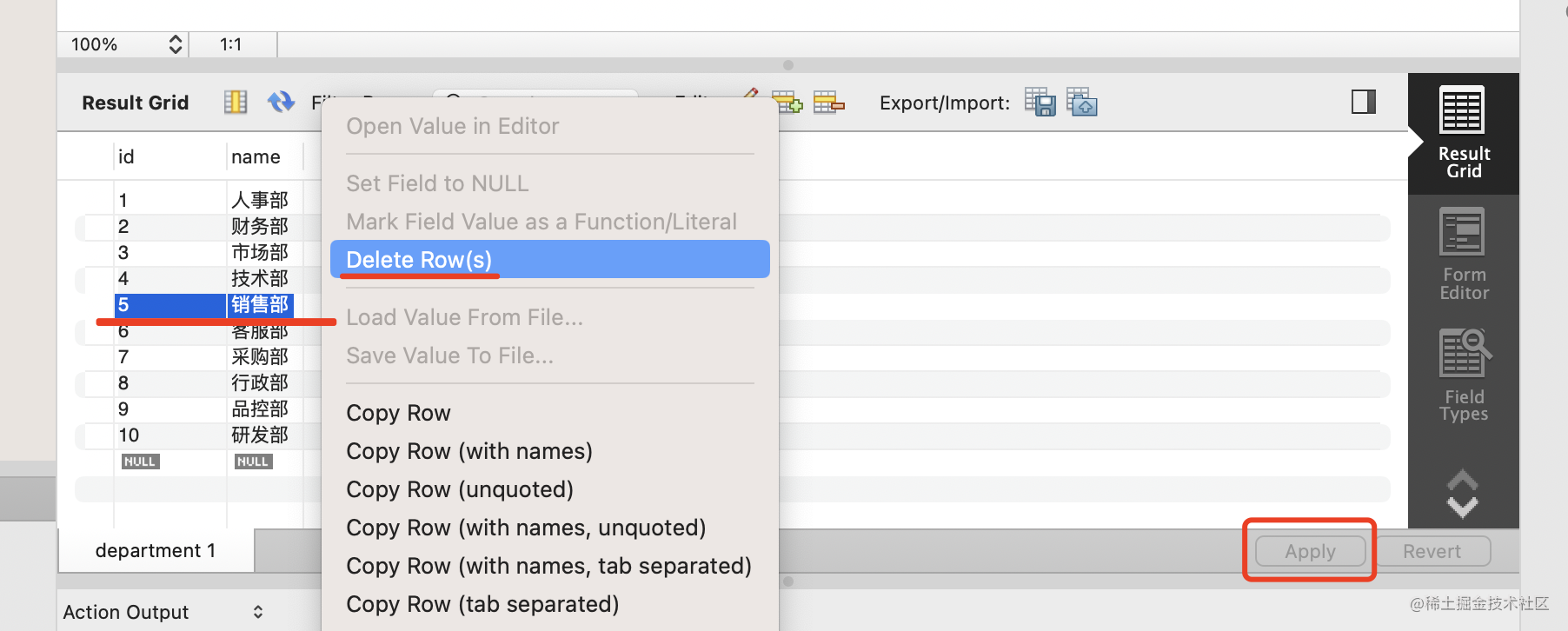
点击 apply。
再查看下员工表,可以看到销售部下的 3 个员工的部门被设置为 null 了:
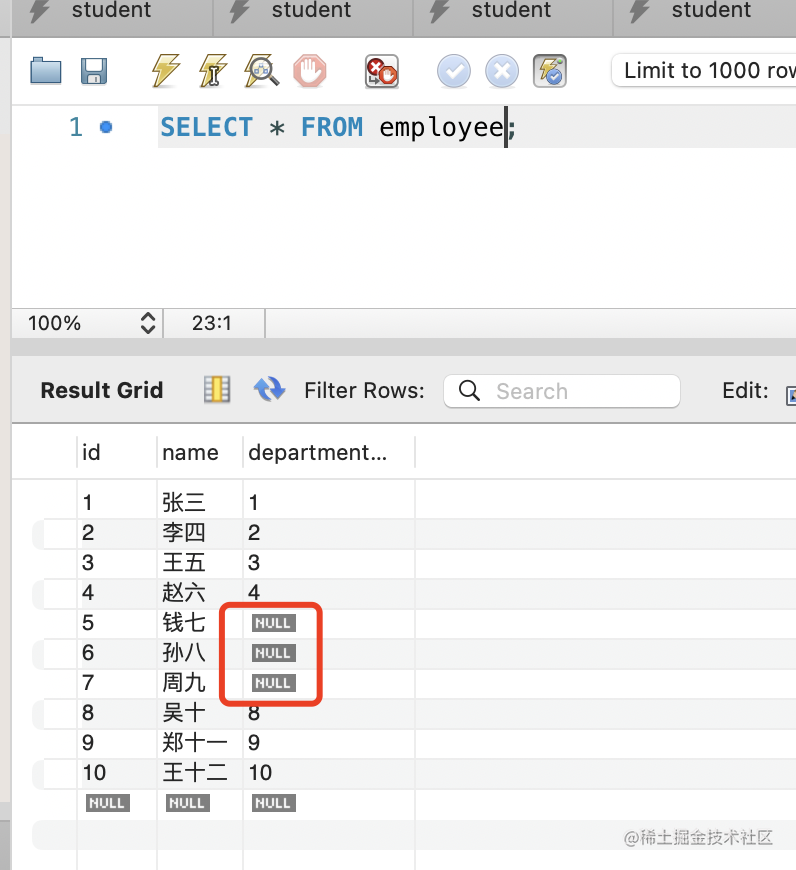
这就是 set null 的级联删除处理。
一对多是不是还挺简单的?
确实,它和一对一没啥本质的区别。
# 接下来我们来看多对多。
比如文章和标签:
之前一对多关系是通过在多的一方添加外键来引用一的一方的 id。
但是现在是多对多了,每一方都是多的一方。这时候是不是双方都要添加外键呢?
一般我们是这样设计:
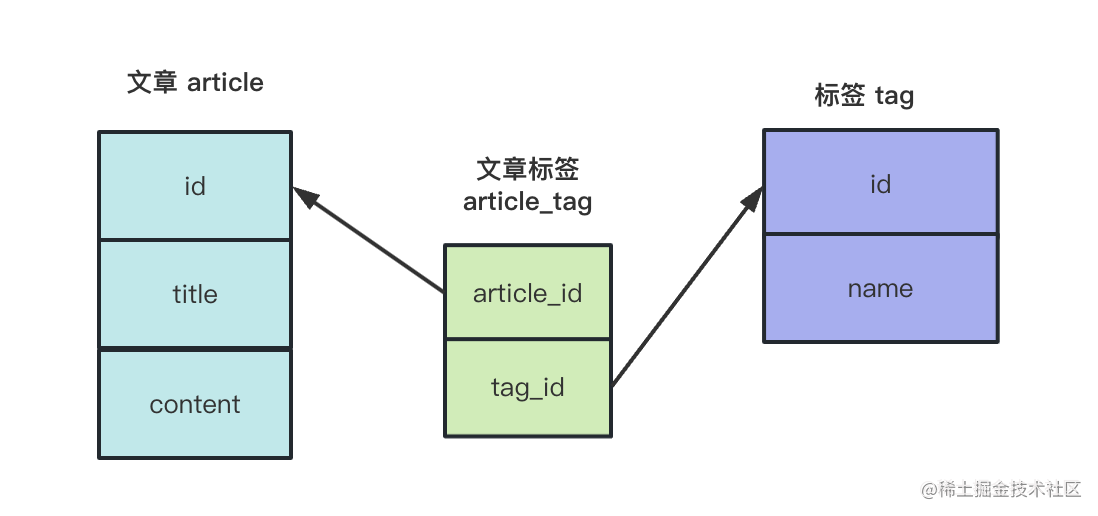
文章一个表、标签一个表,这两个表都不保存外键,然后添加一个中间表来保存双方的外键。
这样文章和标签的关联关系就都被保存到了这个中间表里。
我们试一下:
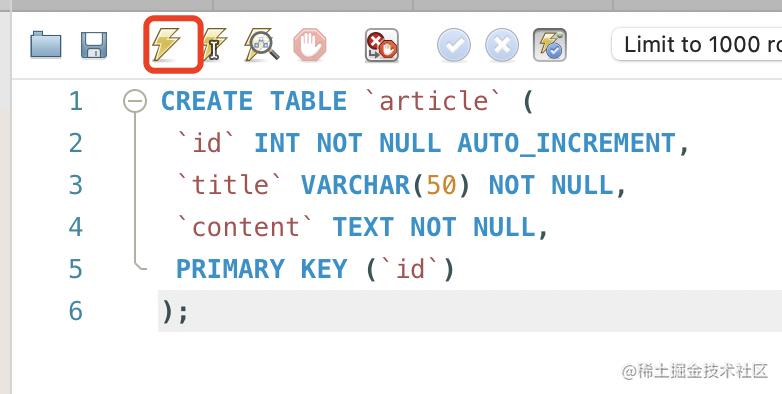
这次我们就直接通过 sql 建表了:
CREATE TABLE `article` (
`id` INT NOT NULL AUTO_INCREMENT,
`title` VARCHAR(50) NOT NULL,
`content` TEXT NOT NULL,
PRIMARY KEY (`id`)
) CHARSET=utf8mb4;
2
3
4
5
6
这里的 TEXT 是长文本类型,可以存储 65535 长度的字符串。
执行这个建表 sql:
查询下:
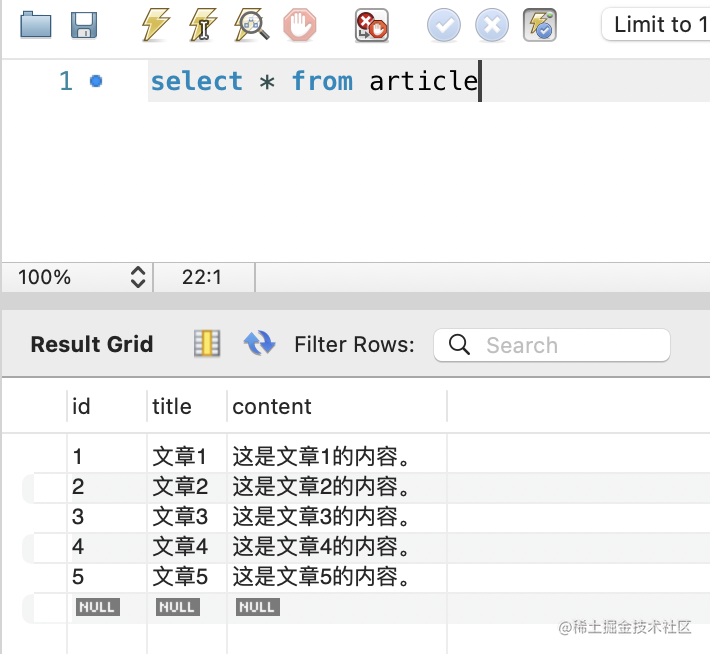
插入几条数据:
INSERT INTO `article` (`title`, `content`)
VALUES
('文章1', '这是文章1的内容。'),
('文章2', '这是文章2的内容。'),
('文章3', '这是文章3的内容。'),
('文章4', '这是文章4的内容。'),
('文章5', '这是文章5的内容。');
2
3
4
5
6
7

再查询下:
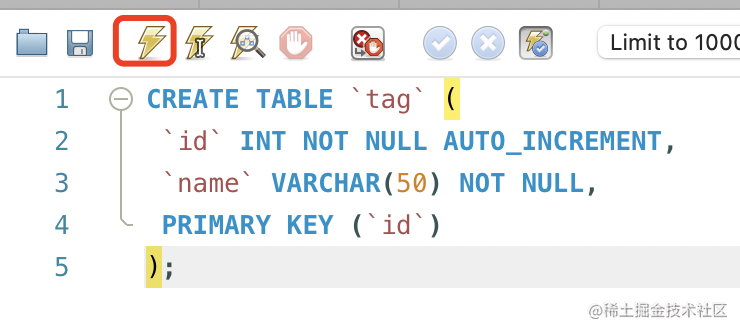
然后创建标签表:
CREATE TABLE `tag` (
`id` INT NOT NULL AUTO_INCREMENT,
`name` VARCHAR(50) NOT NULL,
PRIMARY KEY (`id`)
);
2
3
4
5
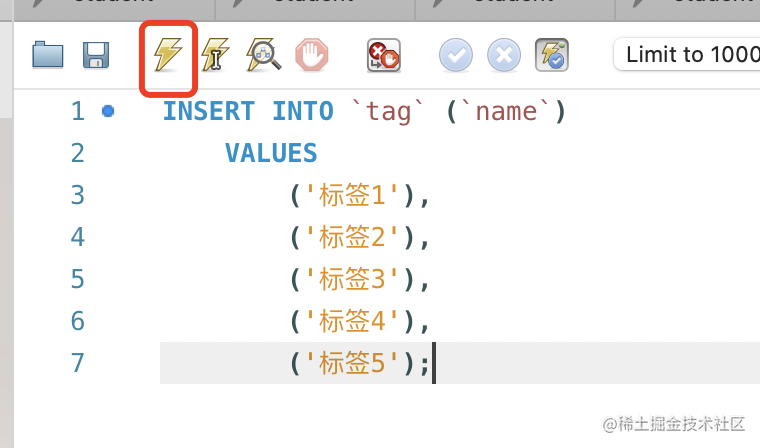
插入几条数据:
INSERT INTO `tag` (`name`)
VALUES
('标签1'),
('标签2'),
('标签3'),
('标签4'),
('标签5');
2
3
4
5
6
7
然后查询下:
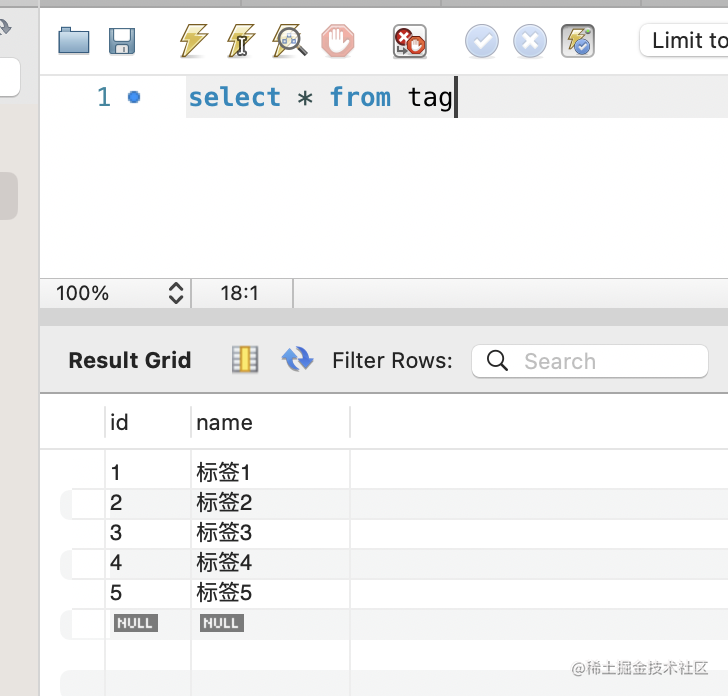
可以看到,建表和插入数据都成功了。
然后创建中间表:
中间表还是通过可视化的方式创建吧:
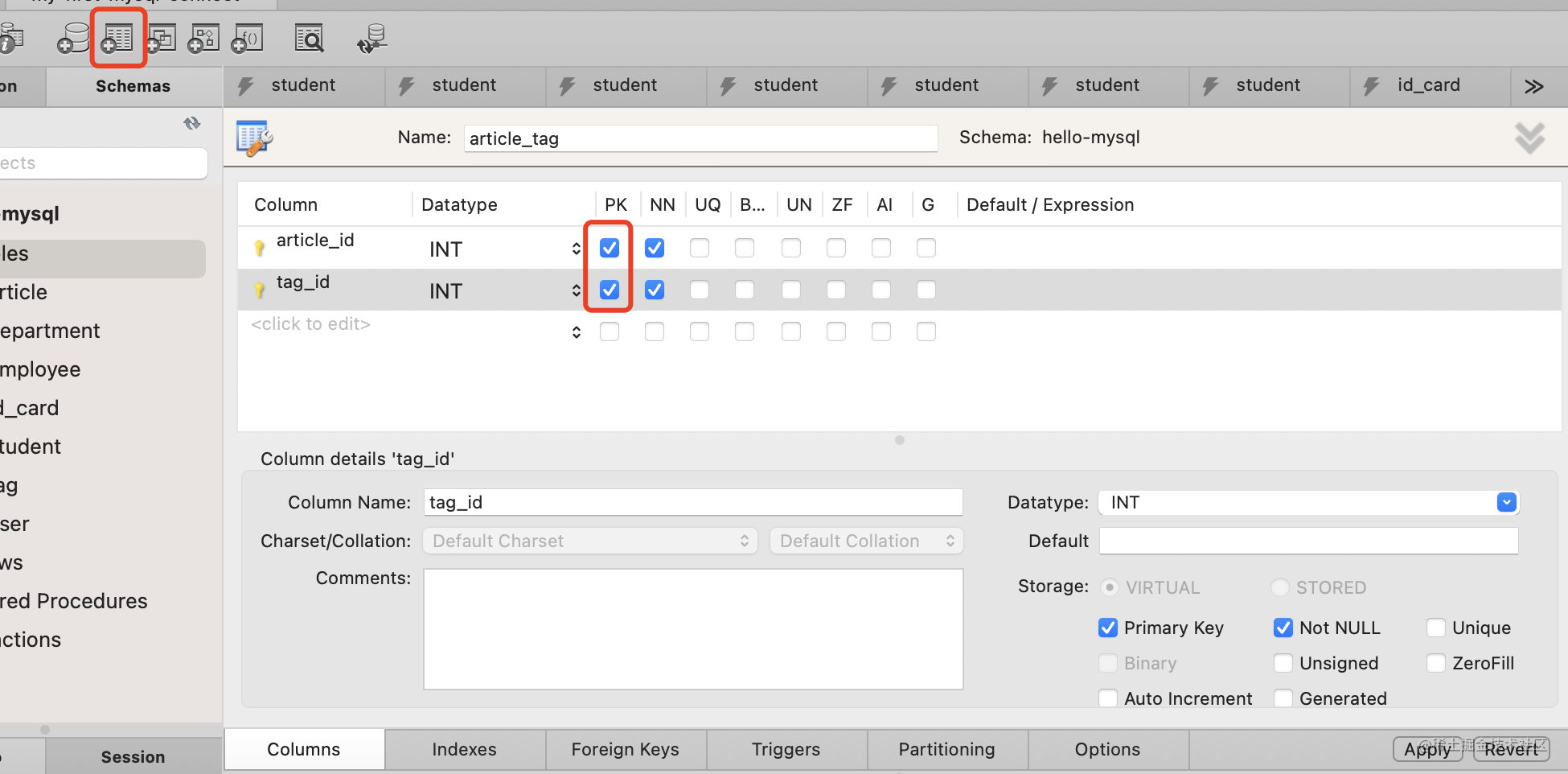
点击创建表,添加 article_id、tag_id 这俩列,设置为 NOT NULL。
注意,这里同时指定这两列为 primary key,也就是复合主键。
添加 article_id 和 tag_id 的外键引用:
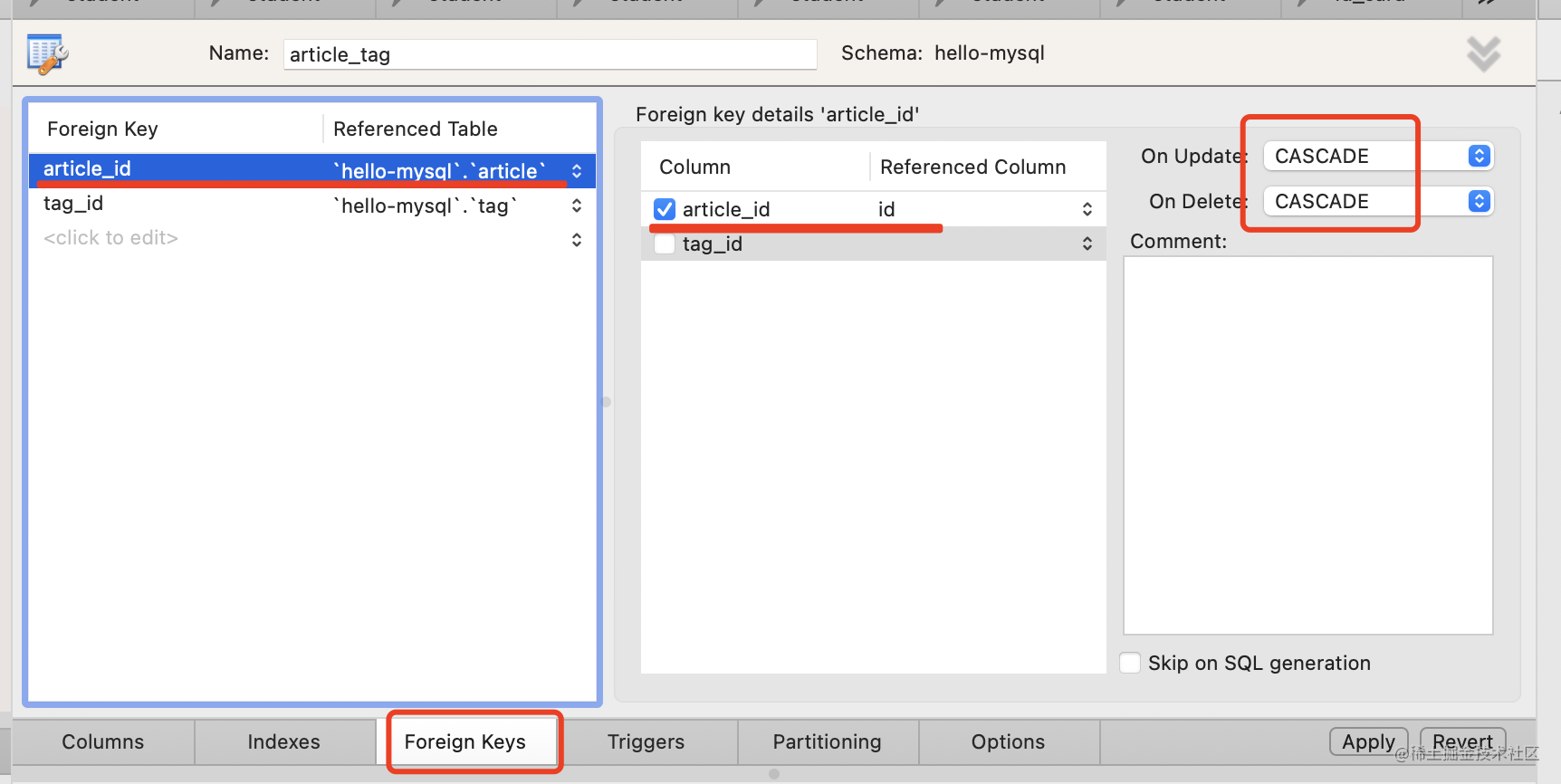
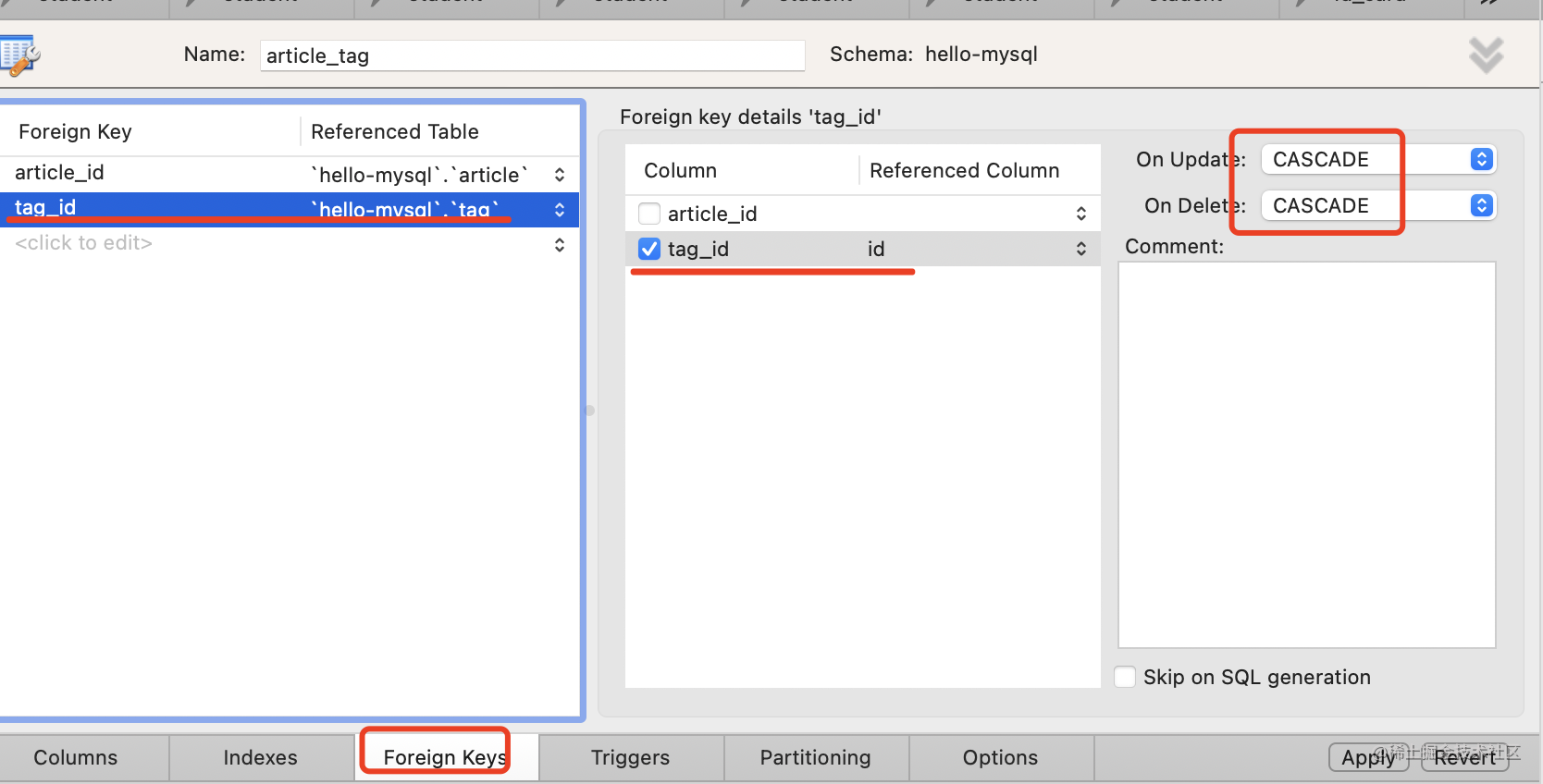
中间表的级联方式要设置为 CASCADE,这个是固定的。
因为它就是用来保存关系的,如果关联的记录都没了,这个关系也就没存在的意义了。
点击 apply,可以看到生成的 sql:
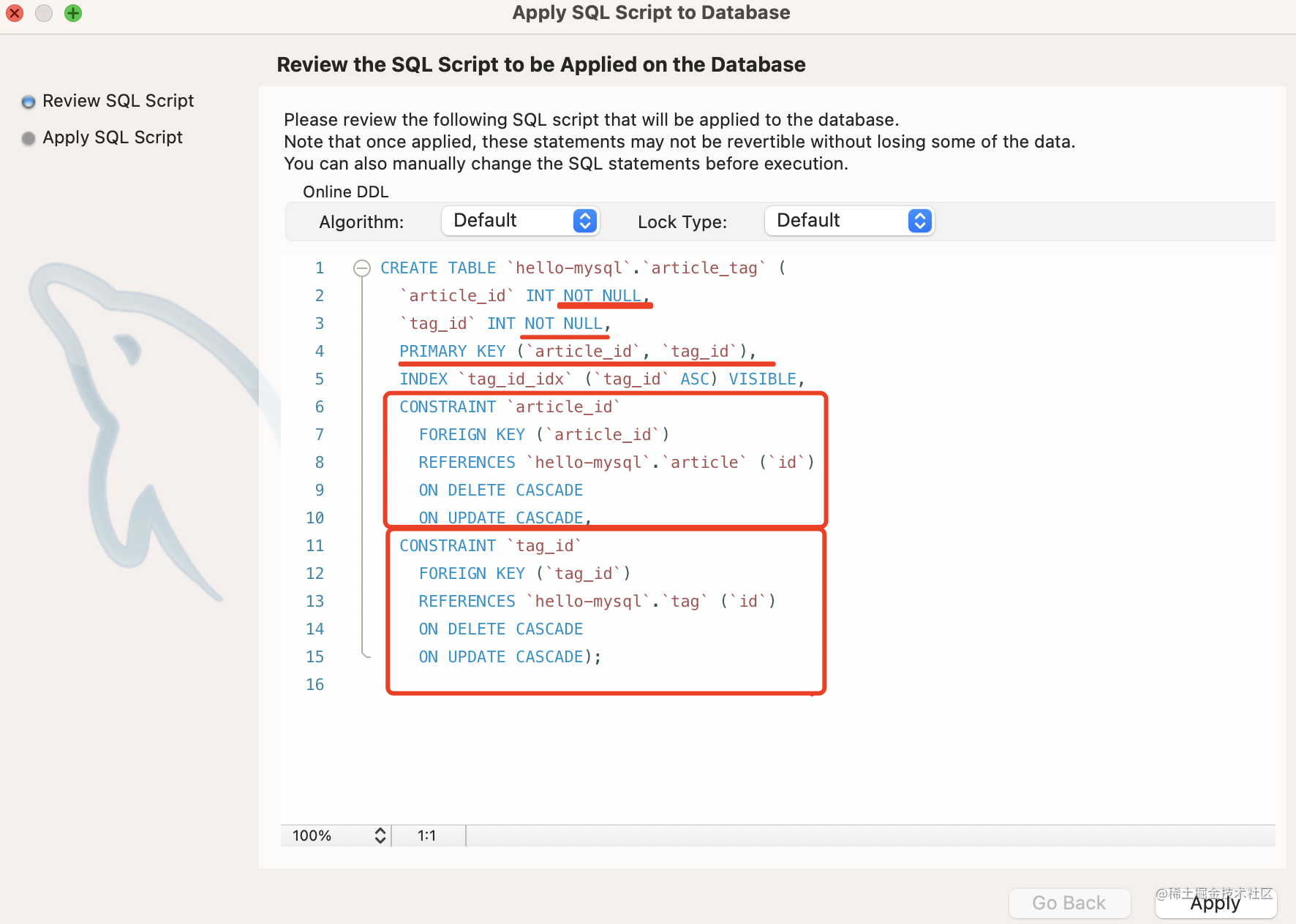
primary key (article_id, tag_id) 是指定复合主键。
后面分别是添加两个外键约束。
建表 sql 能看懂即可,不需要手写。
然后插入几条数据:
INSERT INTO `article_tag` (`article_id`, `tag_id`)
VALUES
(1,1), (1,2), (1,3),
(2,2), (2,3), (2,4),
(3,3), (3,4), (3,5),
(4,4), (4,5), (4,1),
(5,5), (5,1), (5,2);
2
3
4
5
6
7
点击左上角按钮,新建一条 sql:
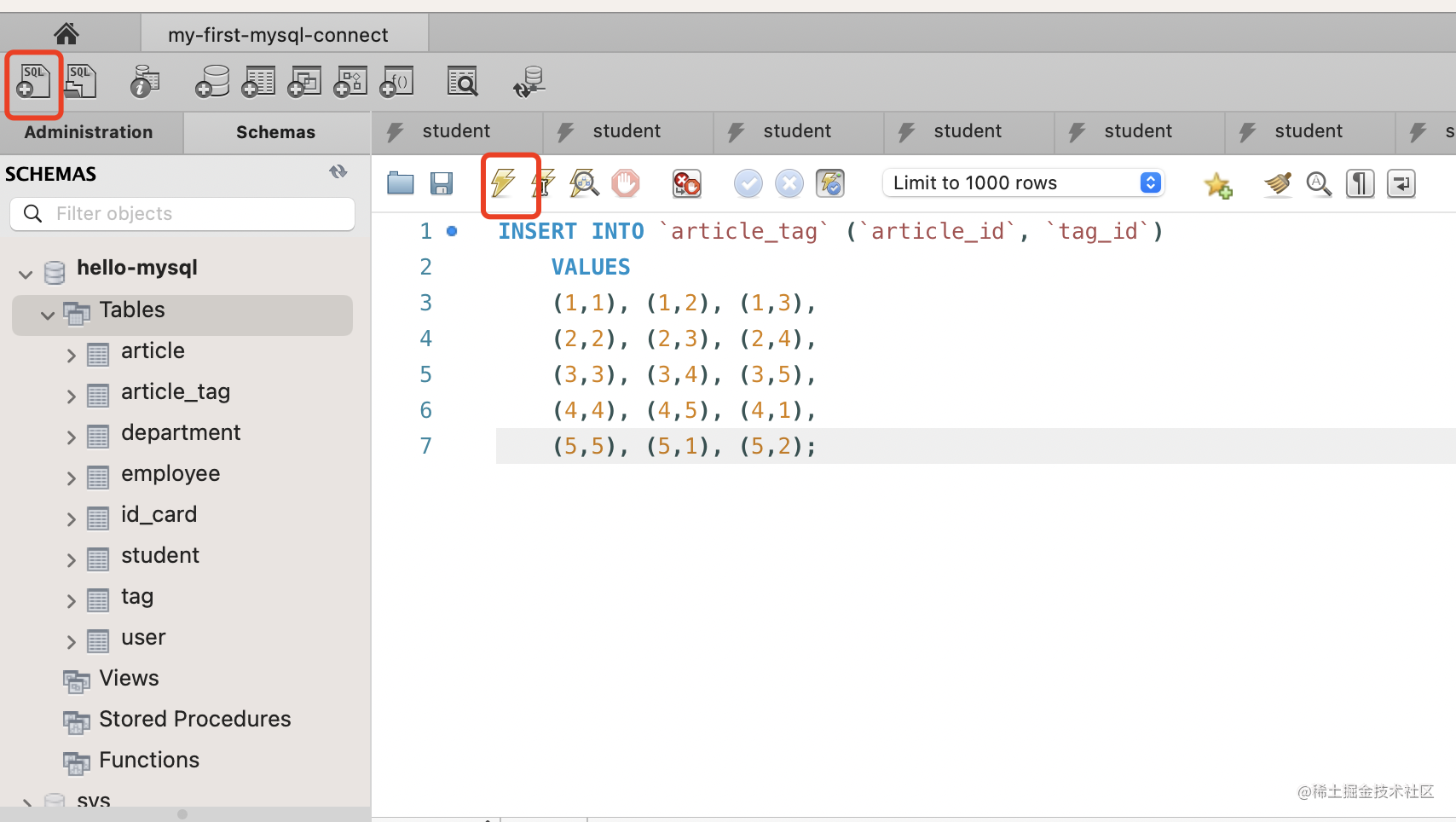
输入 sql 后点击执行。
然后就可以看到插入的数据了:
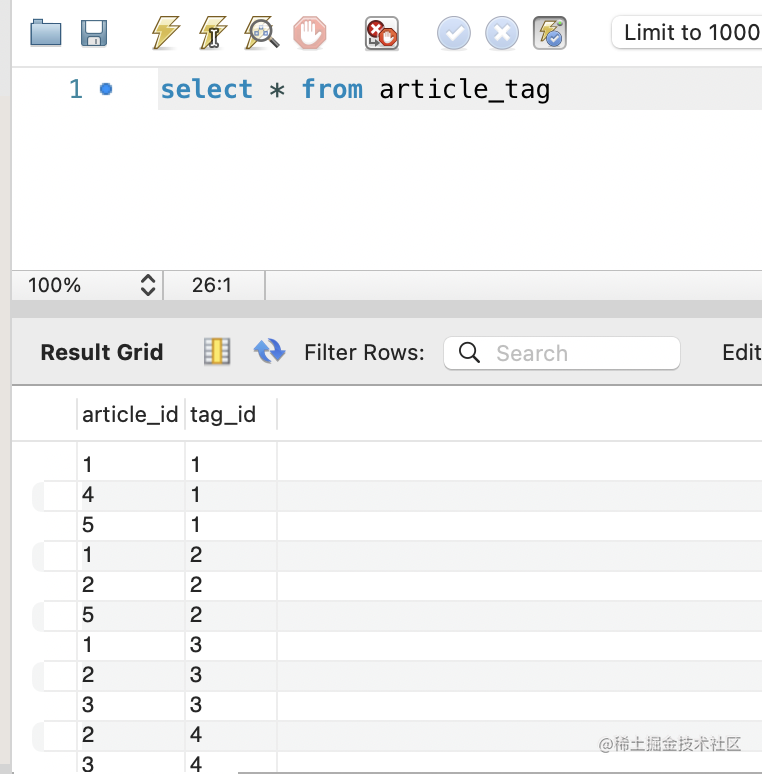
那现在有了 article、tag、article_tag 3 个表了,怎么关联查询呢?
JOIN 3 个表呀!
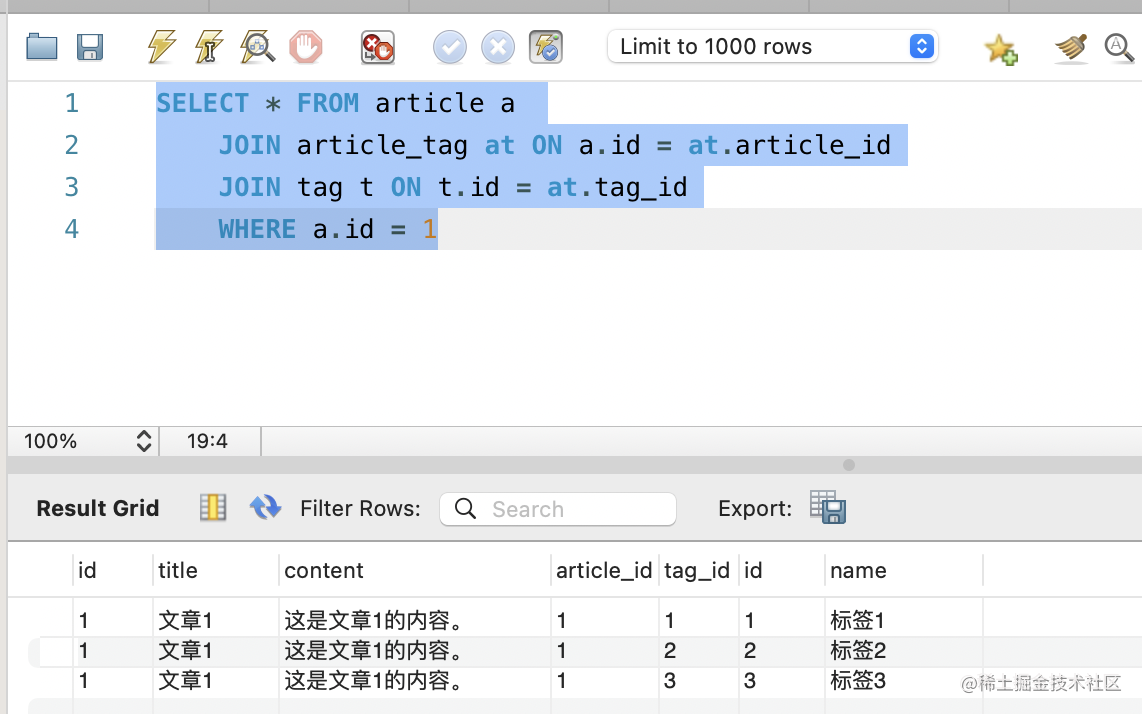
SELECT * FROM article a
JOIN article_tag at ON a.id = at.article_id
JOIN tag t ON t.id = at.tag_id
WHERE a.id = 1
2
3
4
这样查询出的就是 id 为 1 的 article 的所有标签:
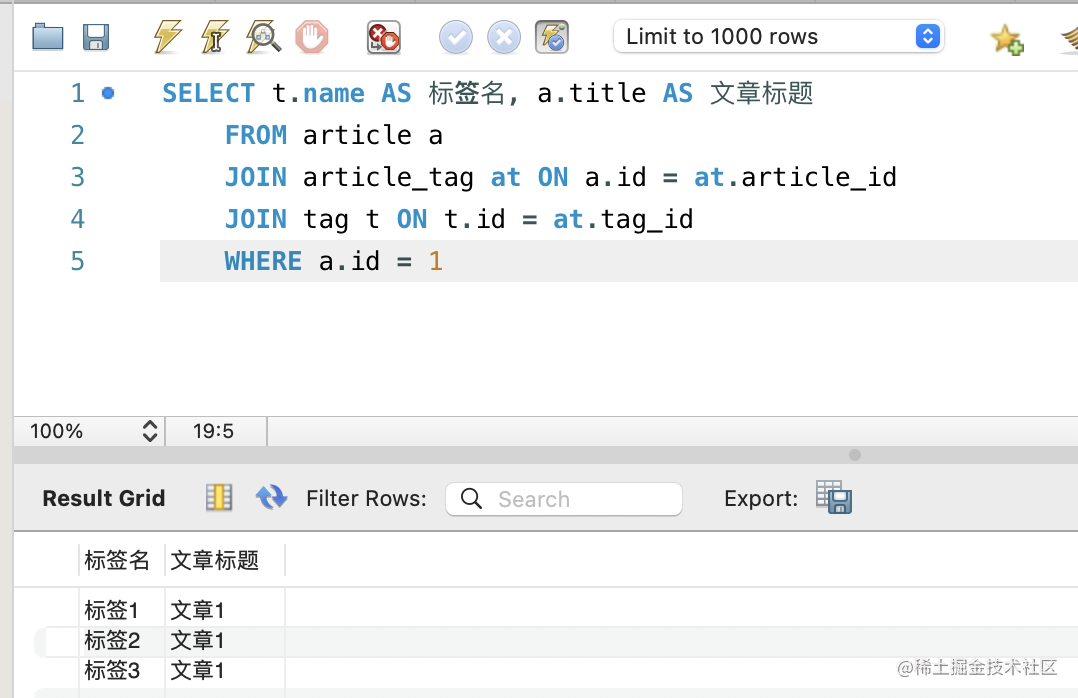
当然,一般我们会指定返回的列:
SELECT t.name AS 标签名, a.title AS 文章标题
FROM article a
JOIN article_tag at ON a.id = at.article_id
JOIN tag t ON t.id = at.tag_id
WHERE a.id = 1
2
3
4
5
此外,我们把文章 1 删除试试:
选中这条 sql 执行:
delete from article where id = 1;
然后再执行下面的查询:
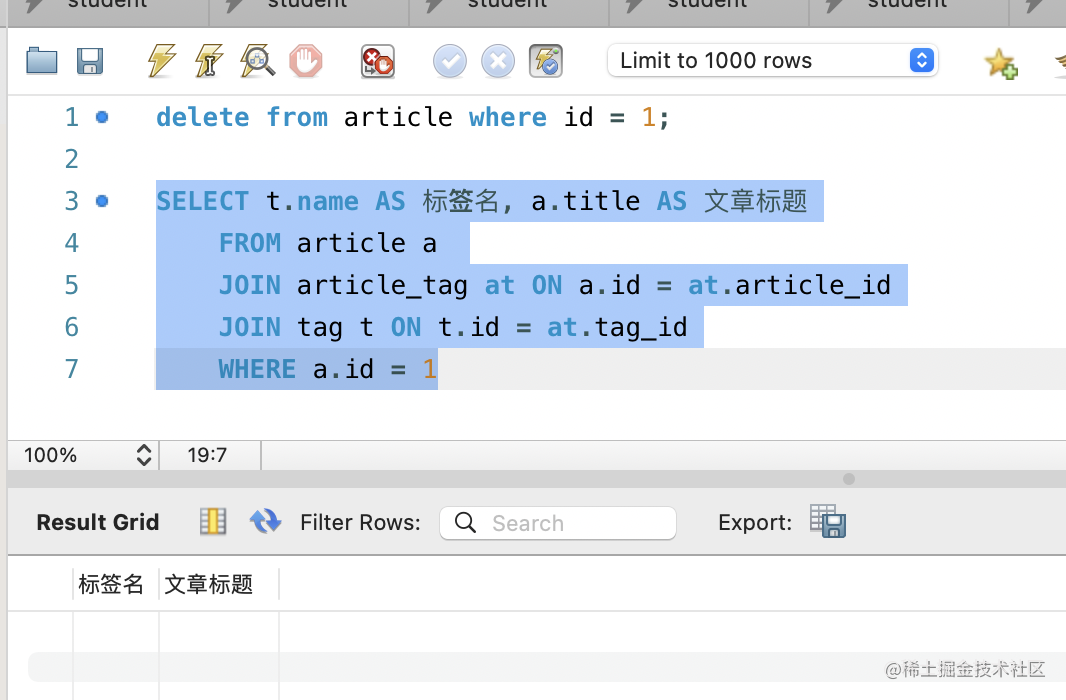
可以看到关系也被级联删除了,这就是 CASCADE 的作用。
当然,删除的只是关系,并不影响 id=1 的标签:
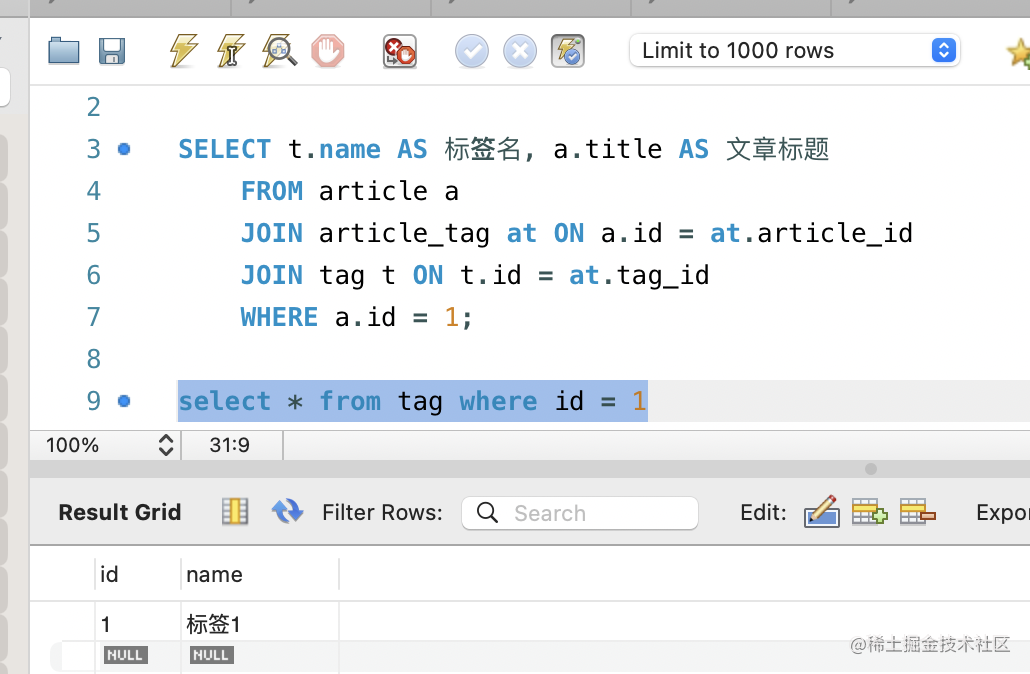
这就是多对多数据的表设计、关联查询和级联方式。
# 总结
现实生活中有很多的一对多、多对多关系。
我们创建了部门、员工表,并在员工表添加了引用部门 id 的外键 department_id 来保存这种一堆多关系。
并且设置了级联方式为 set null。
创建了文章表、标签表、文章标签表来保存多堆多关系,多对多不需要在双方保存彼此的外键,只要在中间表里维护这种关系即可。
中间表的外键级联方式一定为 CASCADE,因为数据没了关系就没必要还留着了。
此外,多对多的 join 需要连接 3 个表来查询。
一对多、多对多是非常常见的表之间的关系,要好好掌握它们的外键设置、关联查询、级联方式 。