
 SQL 查询语句的所有语法和函数
SQL 查询语句的所有语法和函数# 创建 mysql
上节我们学了 mysql 的数据库、表的创建删除,单表的增删改查。
其实增删改查的 sql 语法还有很多,这节我们就来一起过一遍。
用 docker 跑个 mysql 镜像:
上节我们跑 mysql 镜像的时候,把数据保存在了一个目录下,这次把那个目录挂载到新容器的 /var/lib/mysql
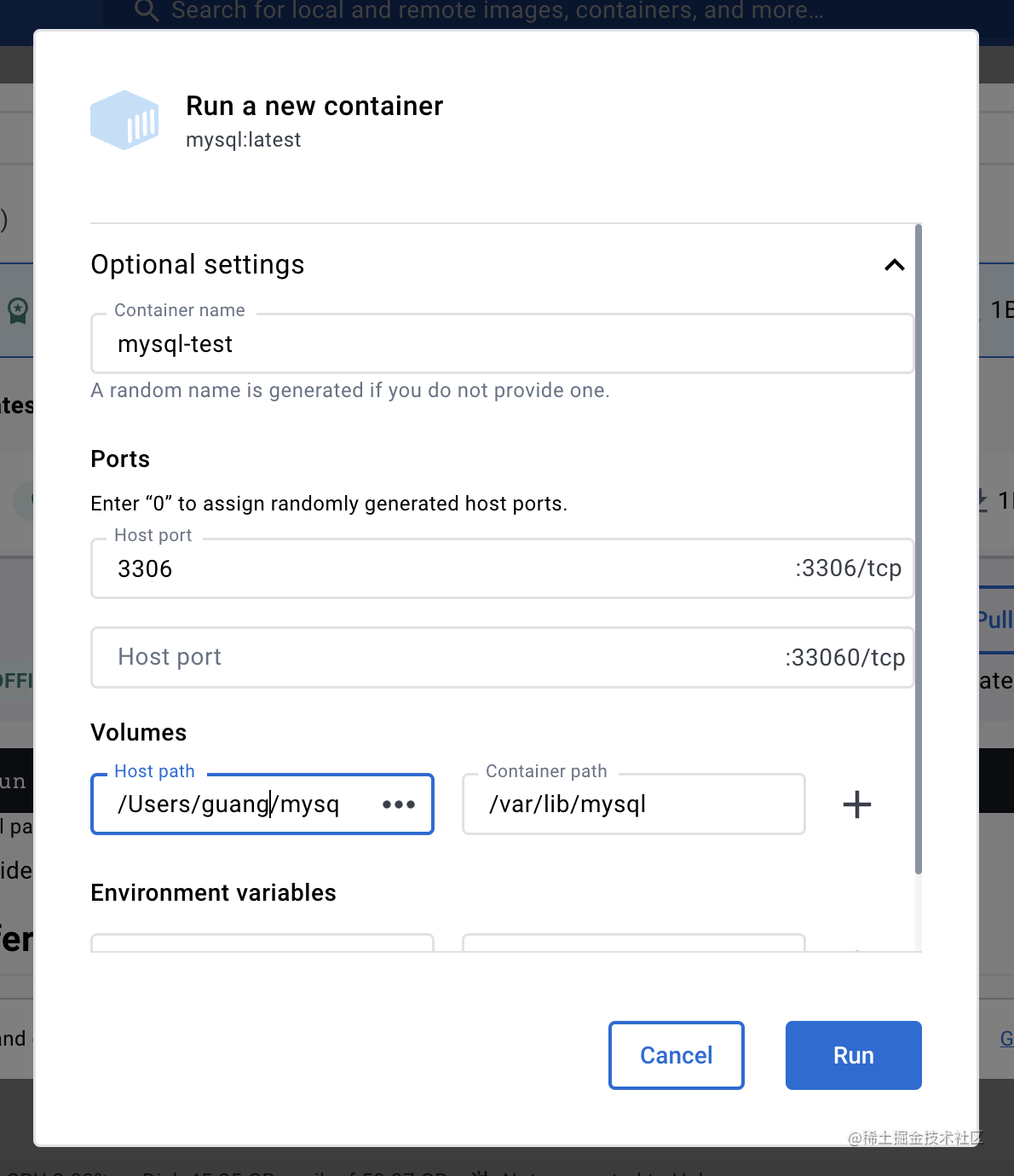
指定容器名、端口映射,点击 run。
这次不用再指定 MYSQL_ROOT_PASSWORD 的环境变量了,因为这个配置同样保存在挂载目录下。
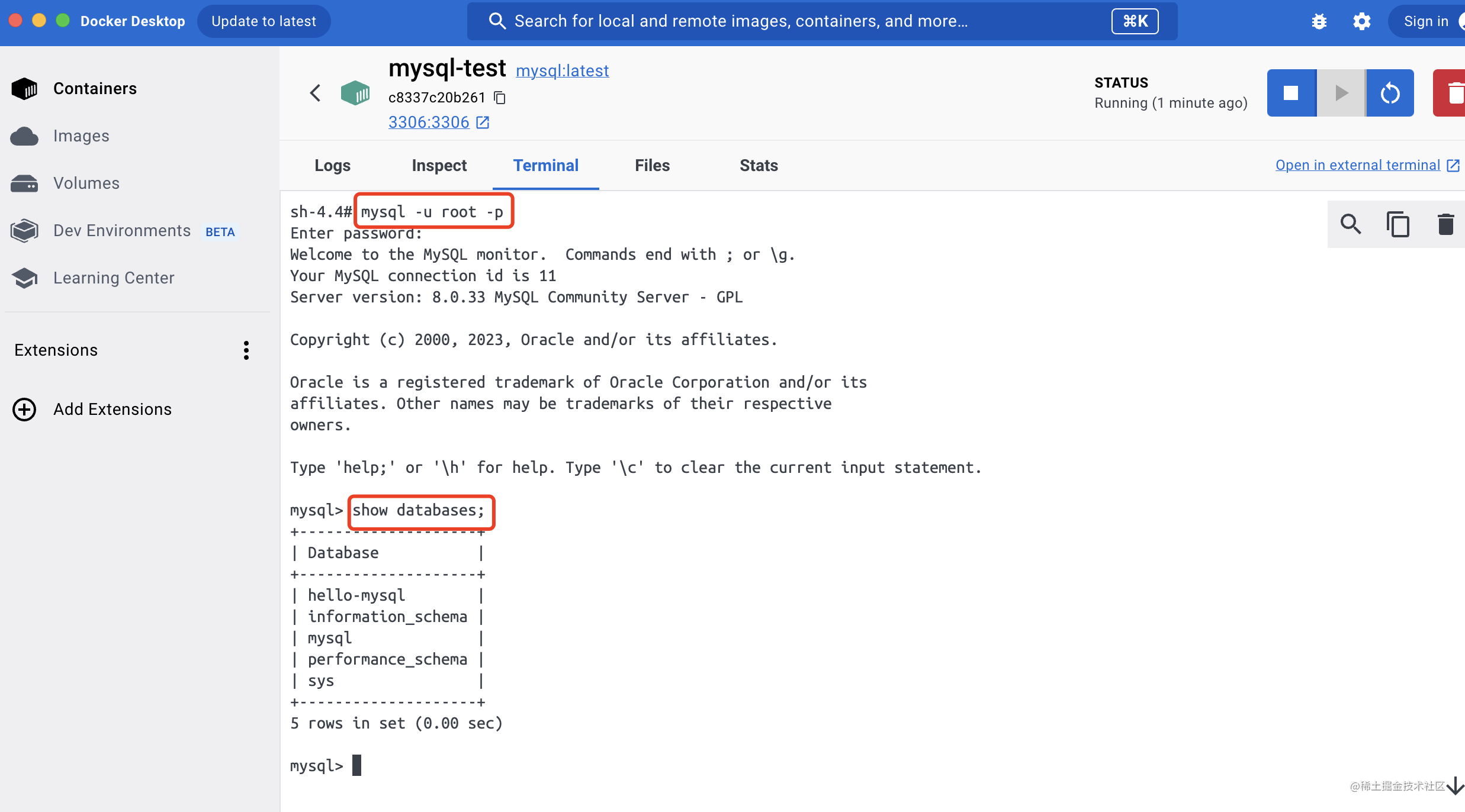
还是用之前的密码连接 mysql,然后 show databases 查看所有数据库。
可以看到上节我们创建的 hello-mysql 数据库还在。
这就是数据卷挂载的用处,就算你跑了个新容器,那只要把数据卷挂上去,数据就能保存下来。
然后还是用 mysql workbench 来连接:
点击之前建的 connection 就行。
# 建表
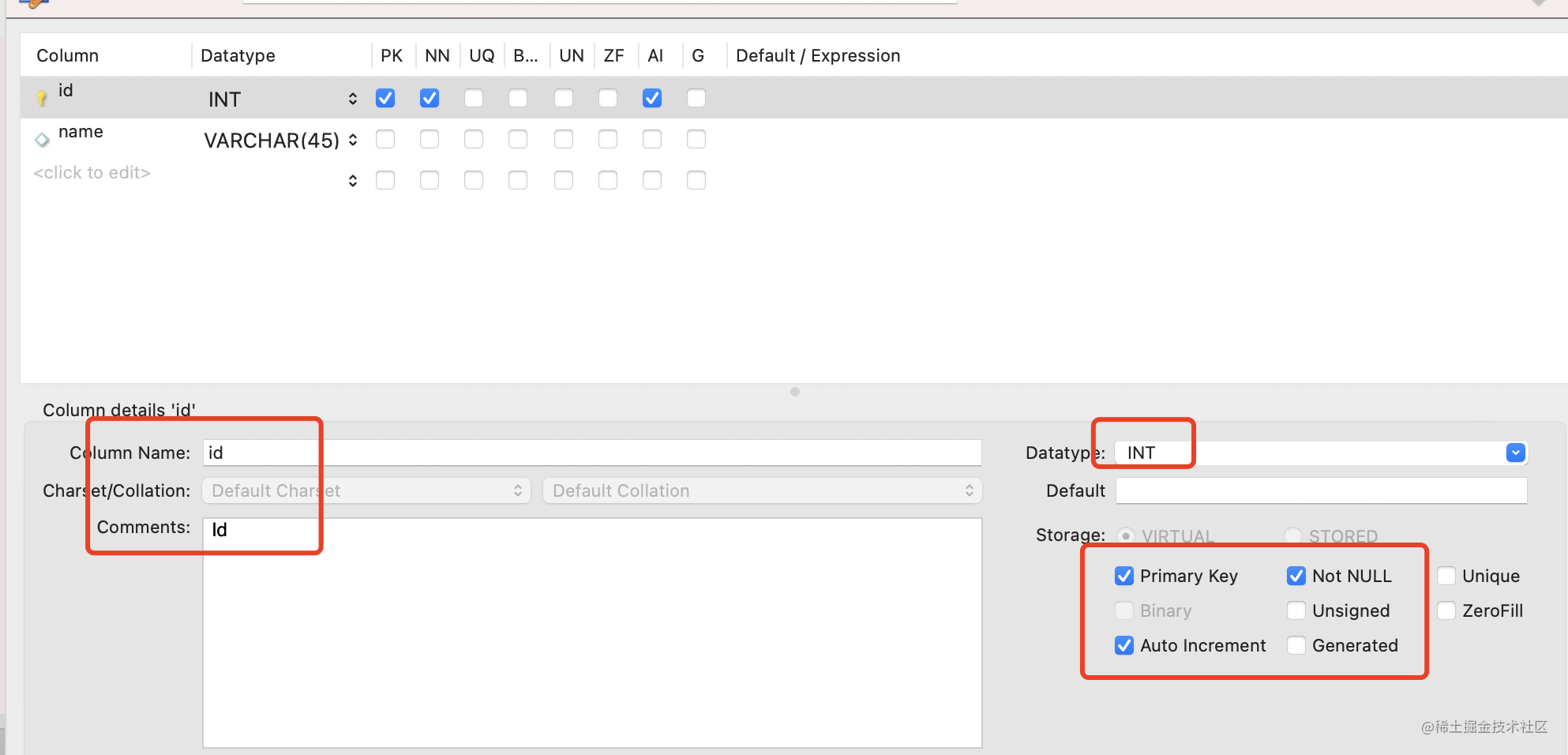
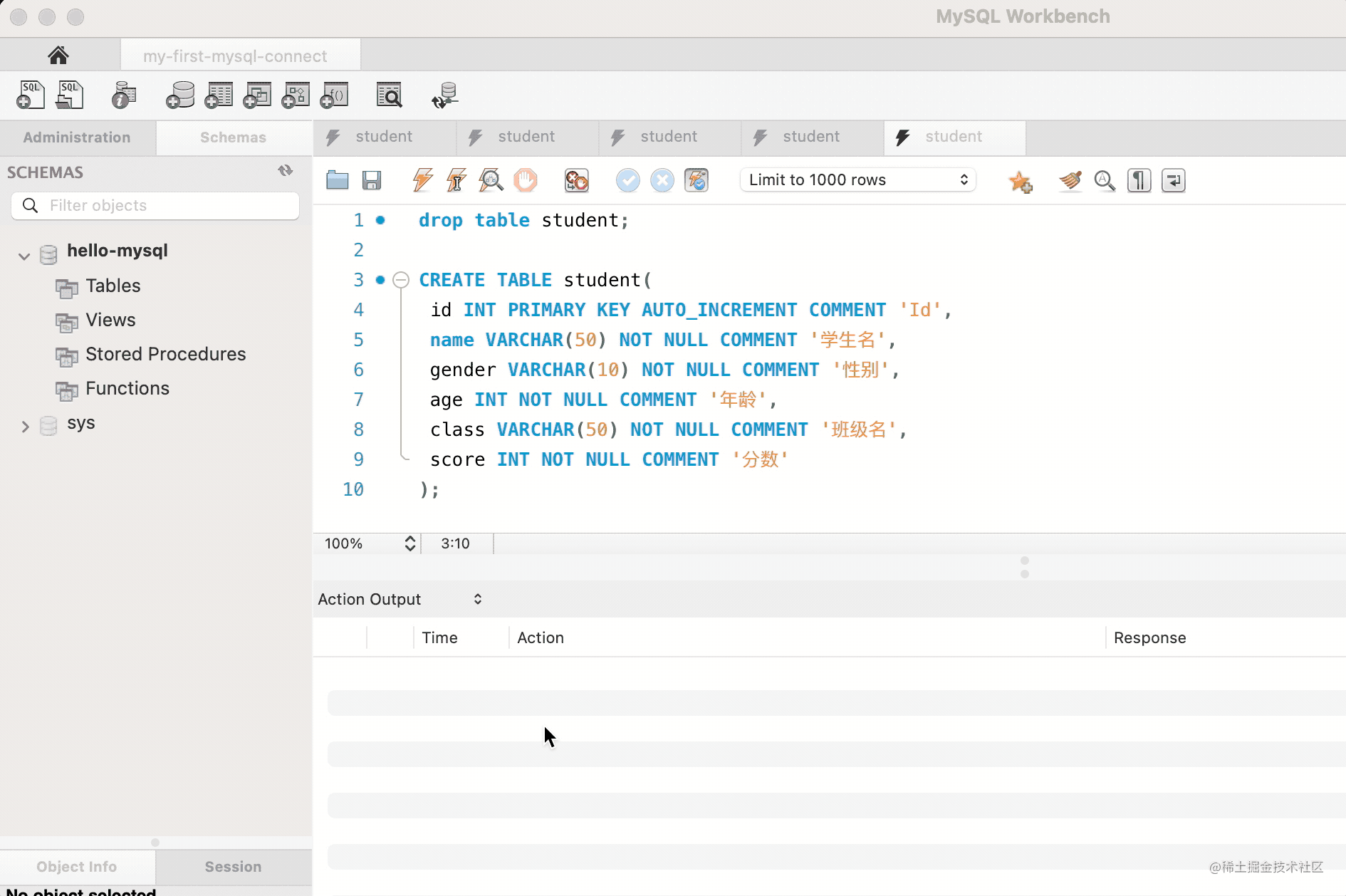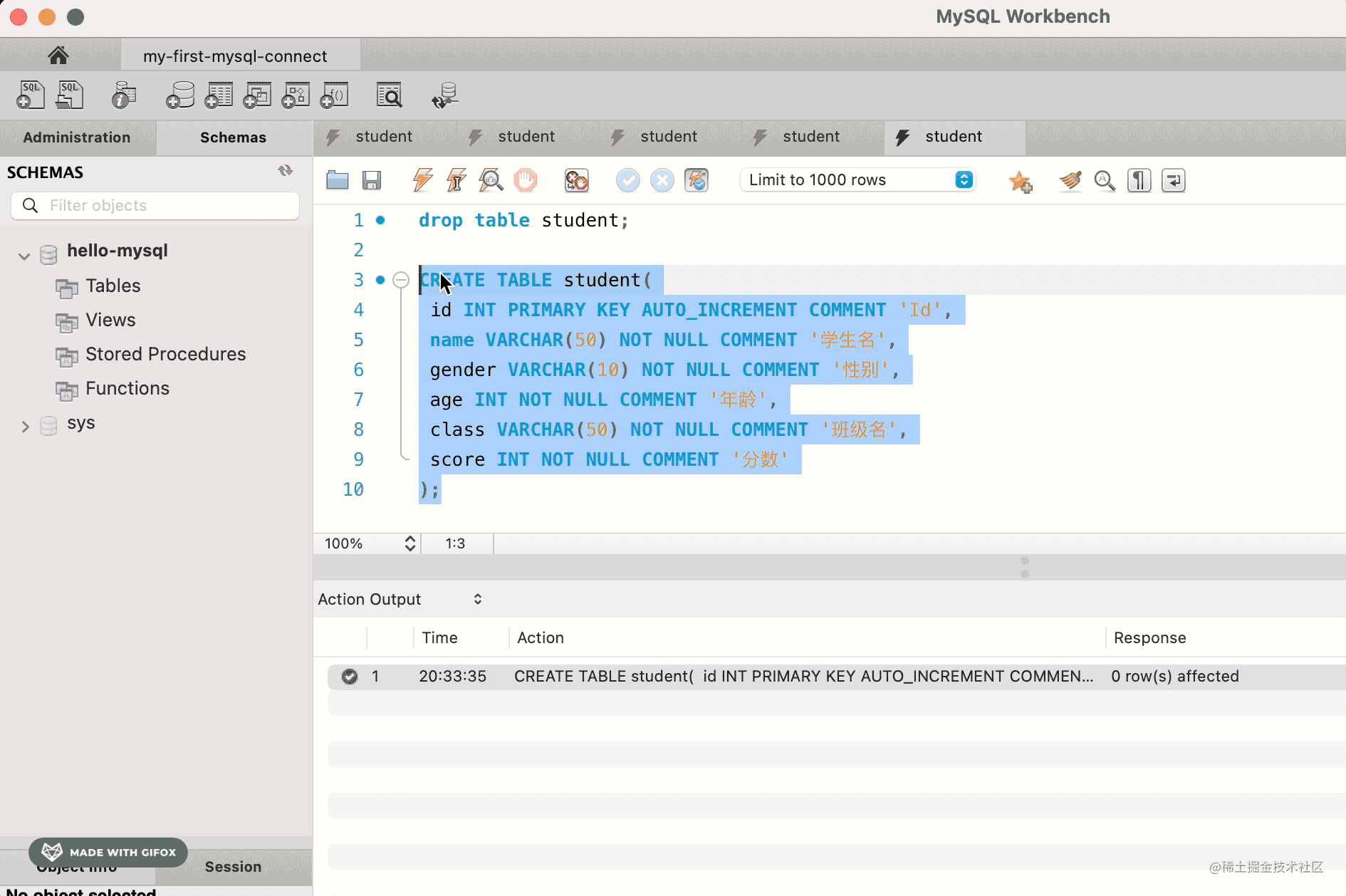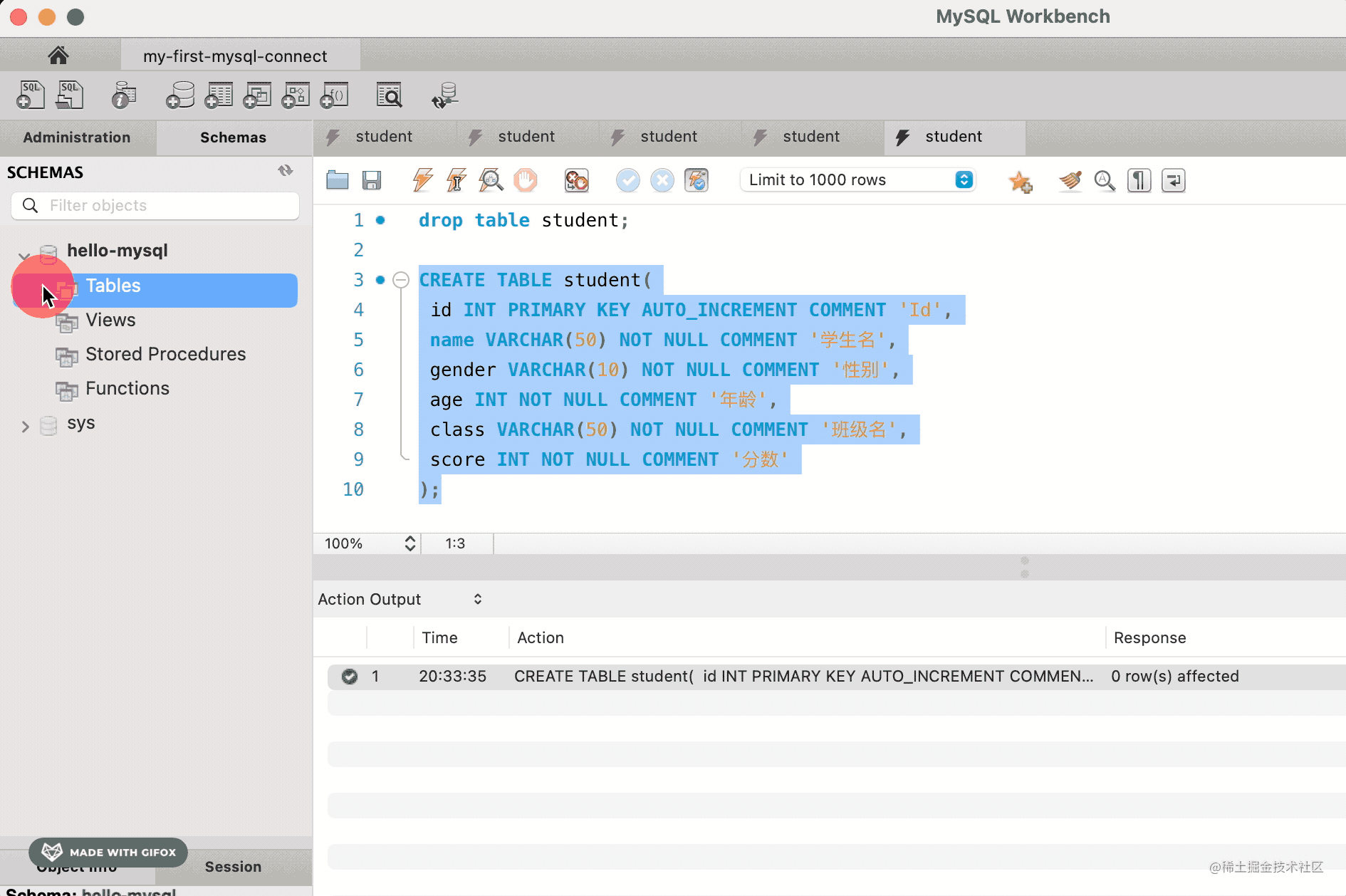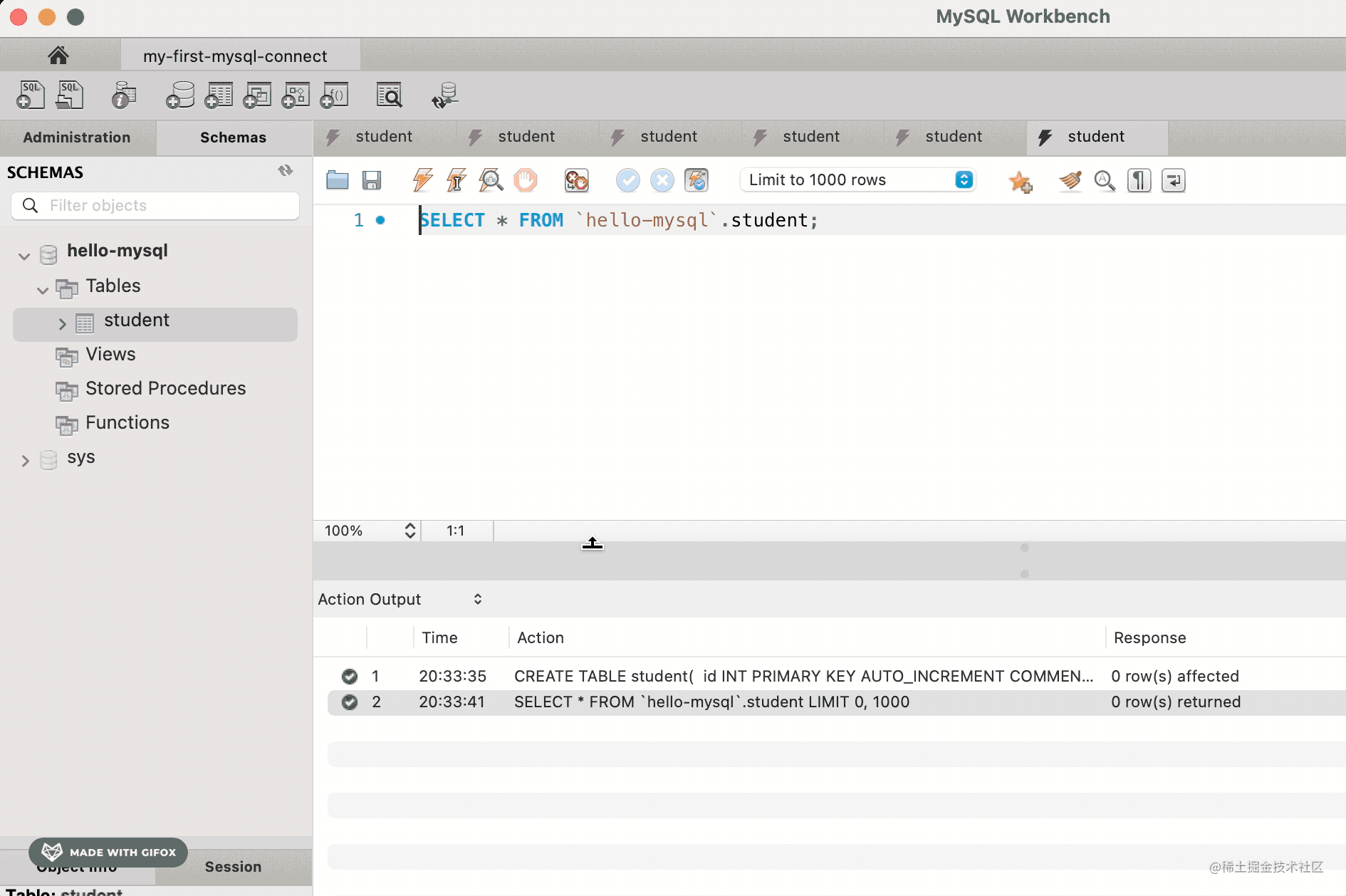
我们先建个表:
CREATE TABLE student(
id INT PRIMARY KEY AUTO_INCREMENT COMMENT 'Id',
name VARCHAR(50) NOT NULL COMMENT '学生名',
gender VARCHAR(10) NOT NULL COMMENT '性别',
age INT NOT NULL COMMENT '年龄',
class VARCHAR(50) NOT NULL COMMENT '班级名',
score INT NOT NULL COMMENT '分数'
) CHARSET=utf8mb4
2
3
4
5
6
7
8
这时学生表。
id 为主键,设置自动增长。
name 为名字,非空。
gender 为性别,非空。
age 为年龄,非空。
class 为班级名,非空。
score 为成绩,非空。
这和你可视化的建表是一样的:
这次我们就通过 sql 建表了。
之前我们建了个 student 表,先把它删掉。
drop table student;
然后执行建表 sql:
然后查询下这个表:
SELECT * FROM student;
没什么数据。
# 插入数据
我们插入一些:
INSERT INTO student (name, gender, age, class, score)
VALUES
('张三', '男',18, '一班',90),
('李四', '女',19, '二班',85),
('王五', '男',20, '三班',70),
('赵六', '女',18, '一班',95),
('钱七', '男',19, '二班',80),
('孙八', '女',20, '三班',75),
('周九', '男',18, '一班',85),
('吴十', '女',19, '二班',90),
('郑十一', '男',20, '三班',60),
('王十二', '女',18, '一班',95),
('赵十三', '男',19, '二班',75),
('钱十四', '女',20, '三班',80),
('孙十五', '男',18, '一班',90),
('周十六', '女',19, '二班',85),
('吴十七', '男',20, '三班',70),
('郑十八', '女',18, '一班',95),
('王十九', '男',19, '二班',80),
('赵二十', '女',20, '三班',75);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
id 是自动递增的,不需要指定。
先选中执行 insert,再选中执行 select:
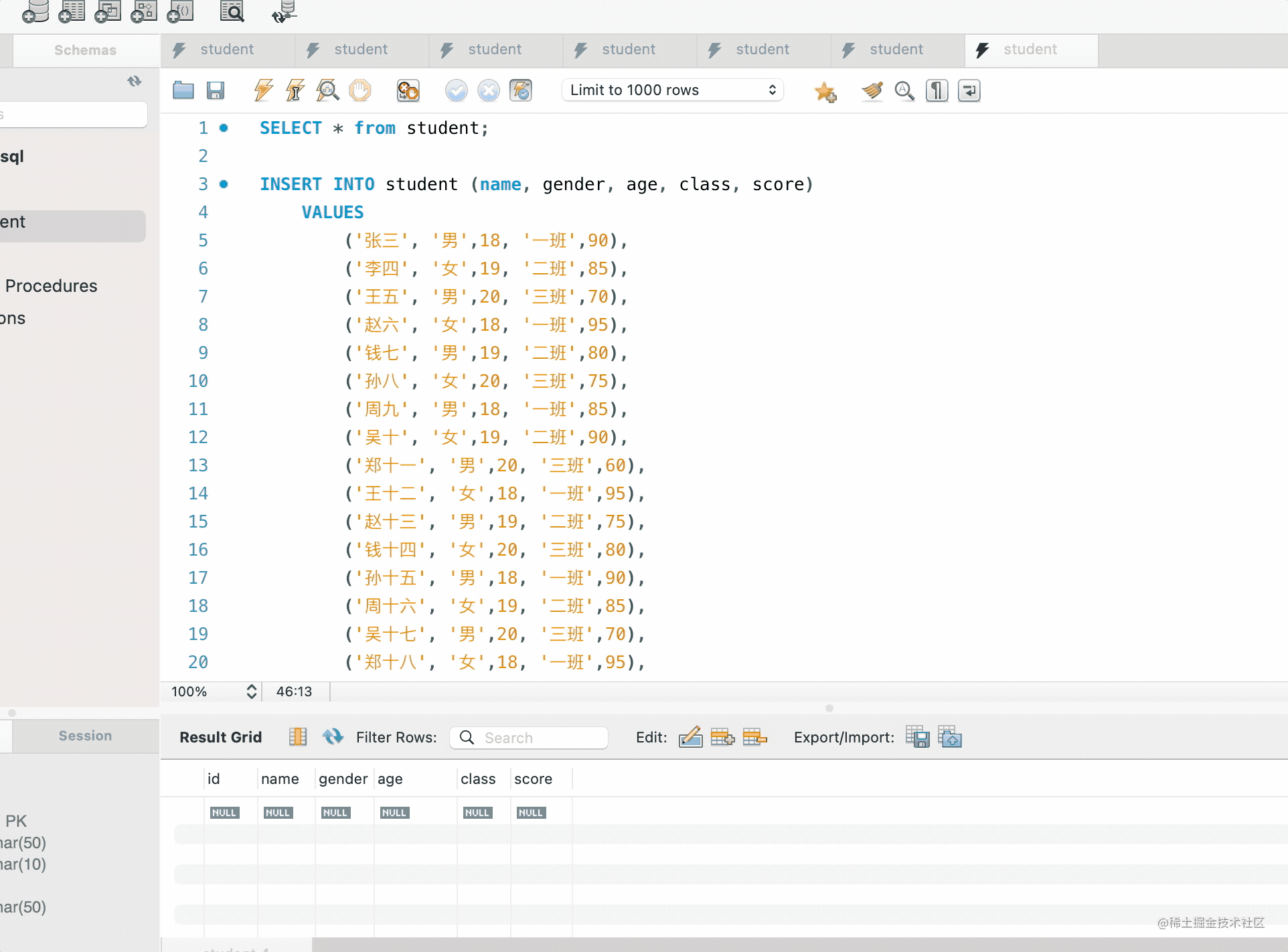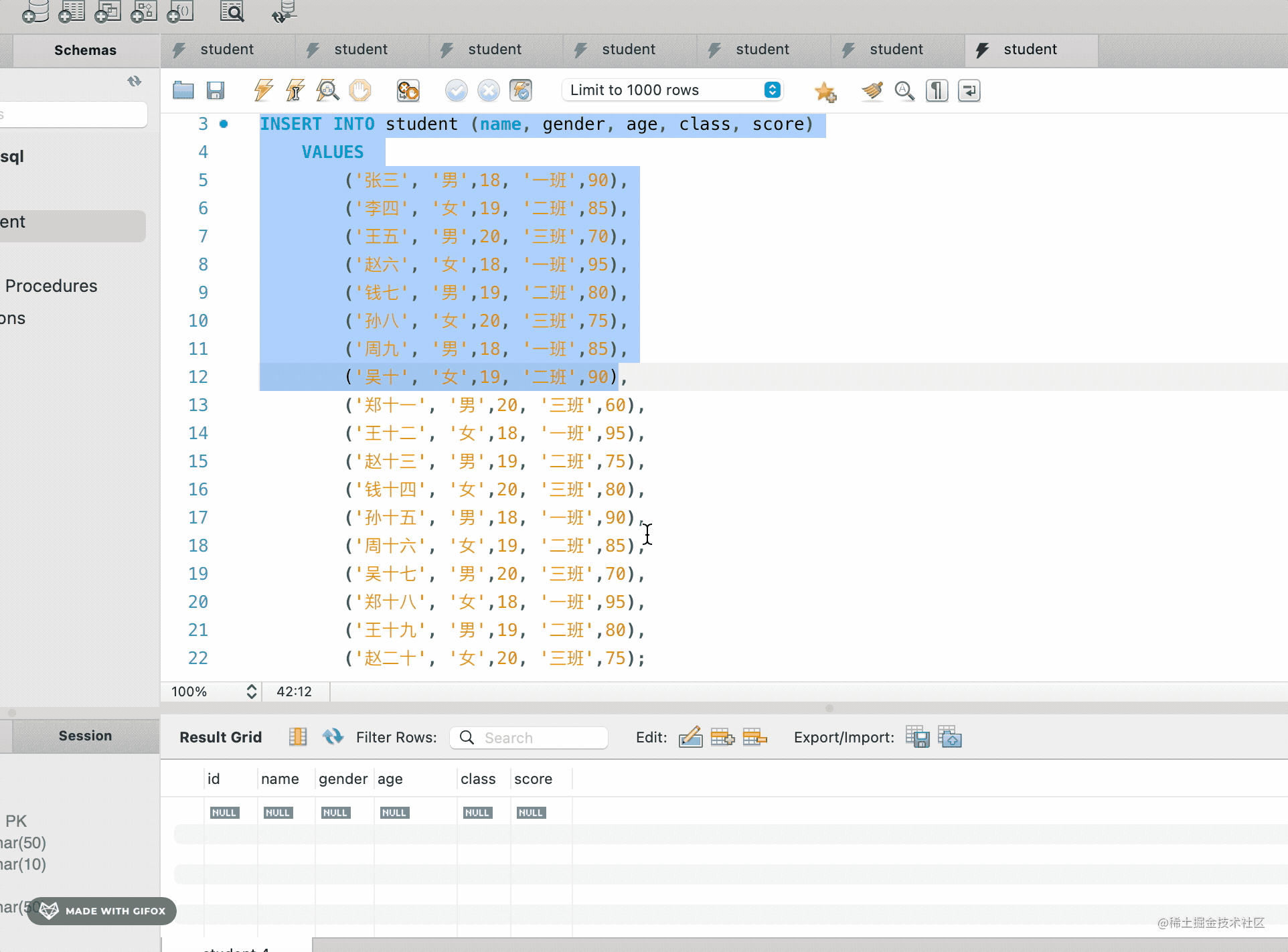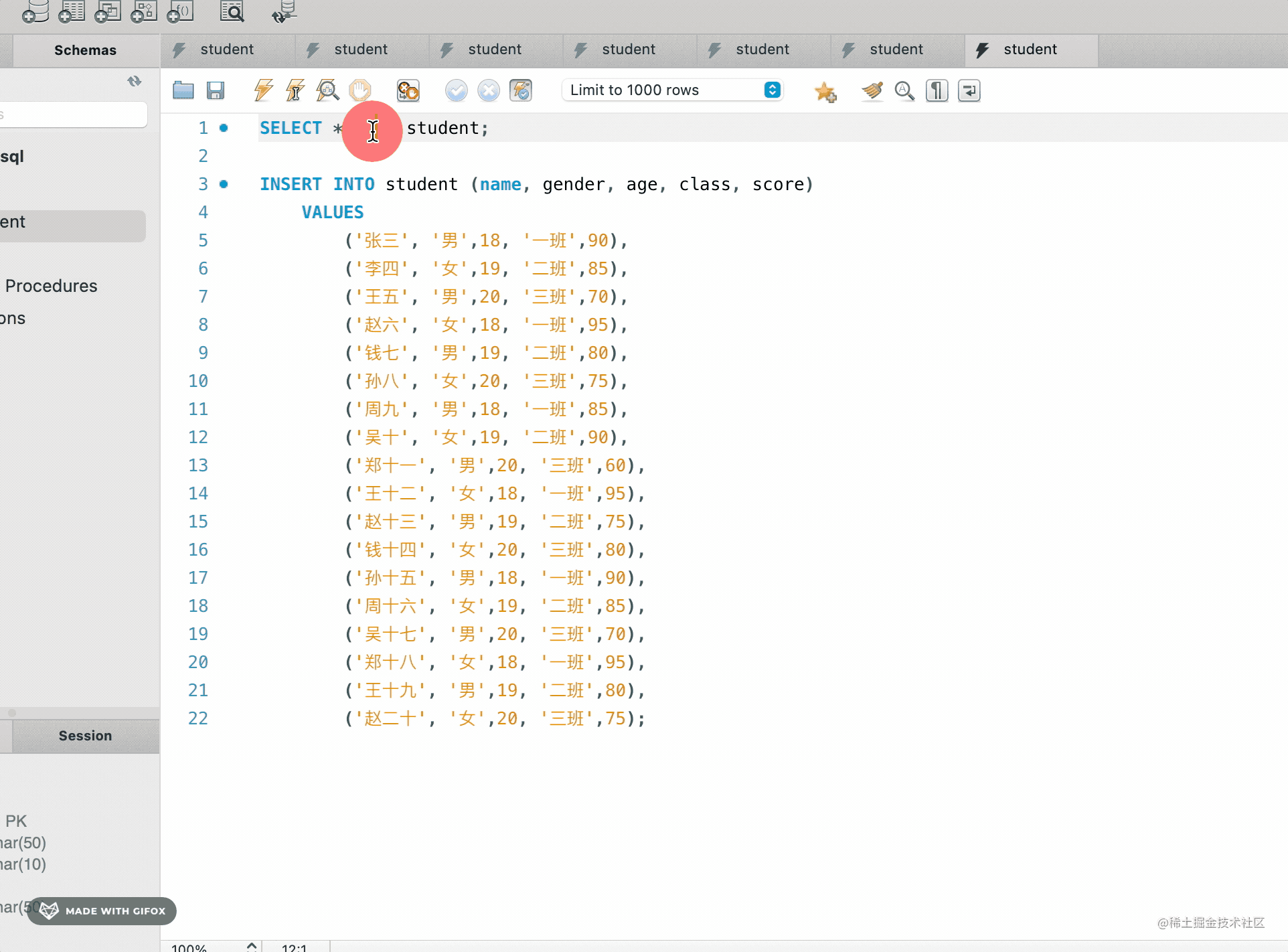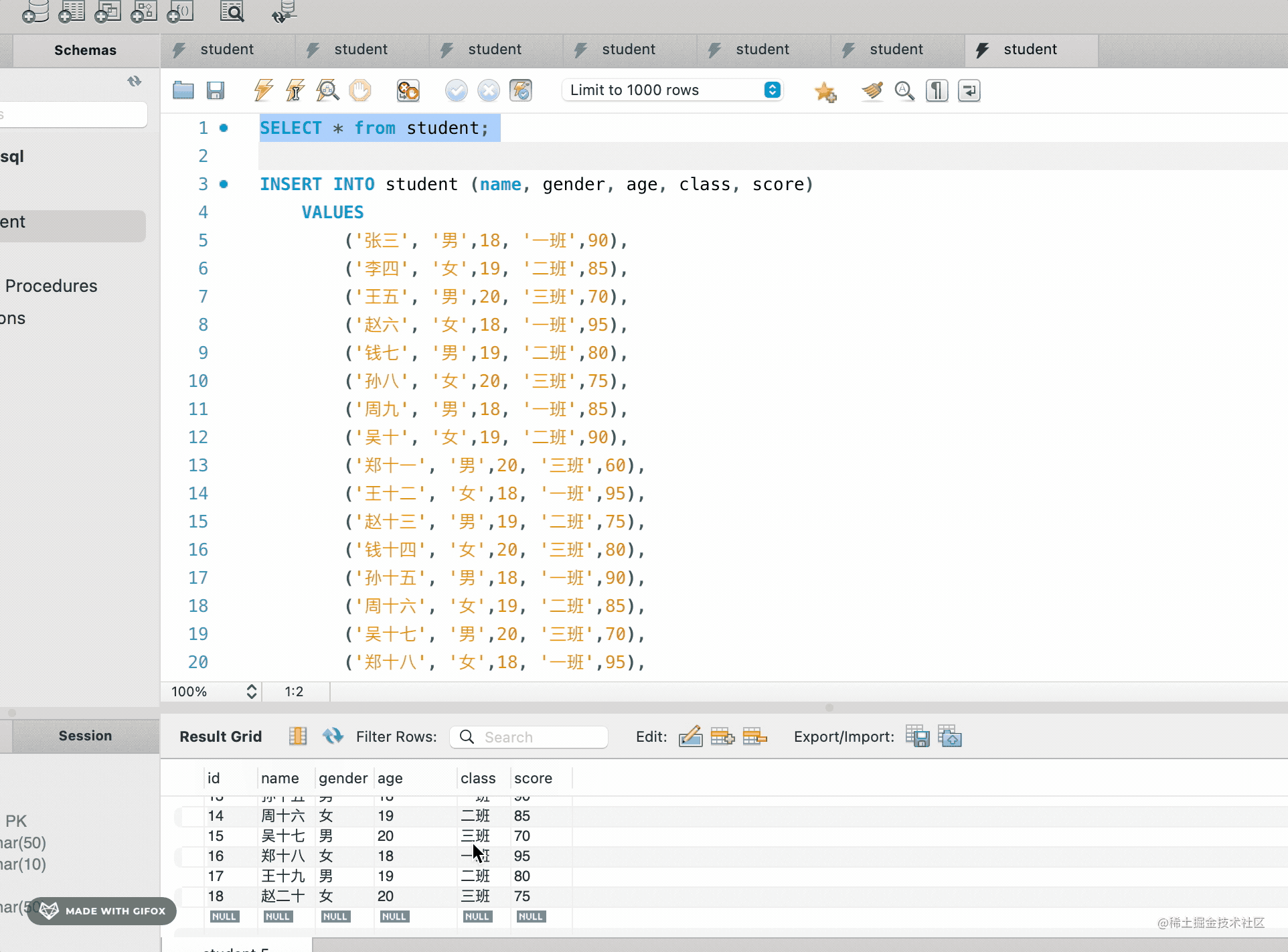
插入了这样 18 条数据:
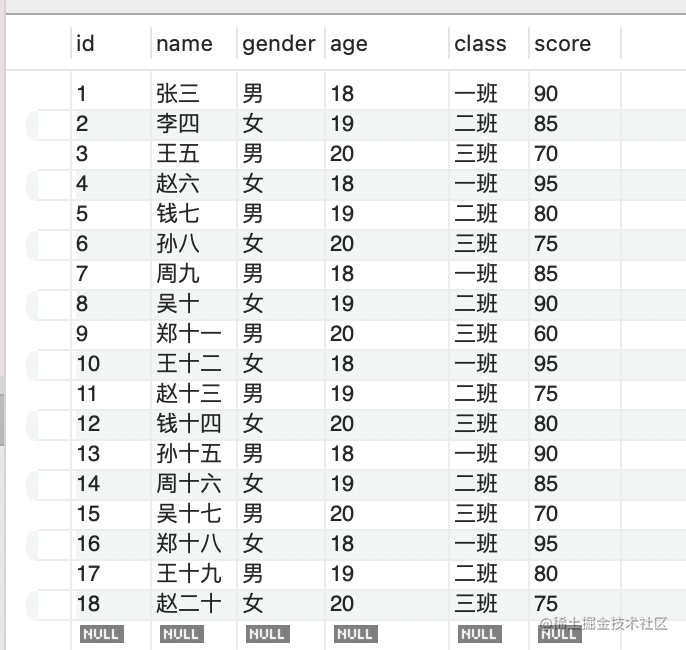
接下来就用这些数据来练习 sql:
# 查询
首先,查询是可以指定查询的列的:
SELECT name, score FROM student;
之前 select * 是查询所有列的意思。
可以通过 as 修改返回的列名:
SELECT name as 名字, score as 分数 FROM student;
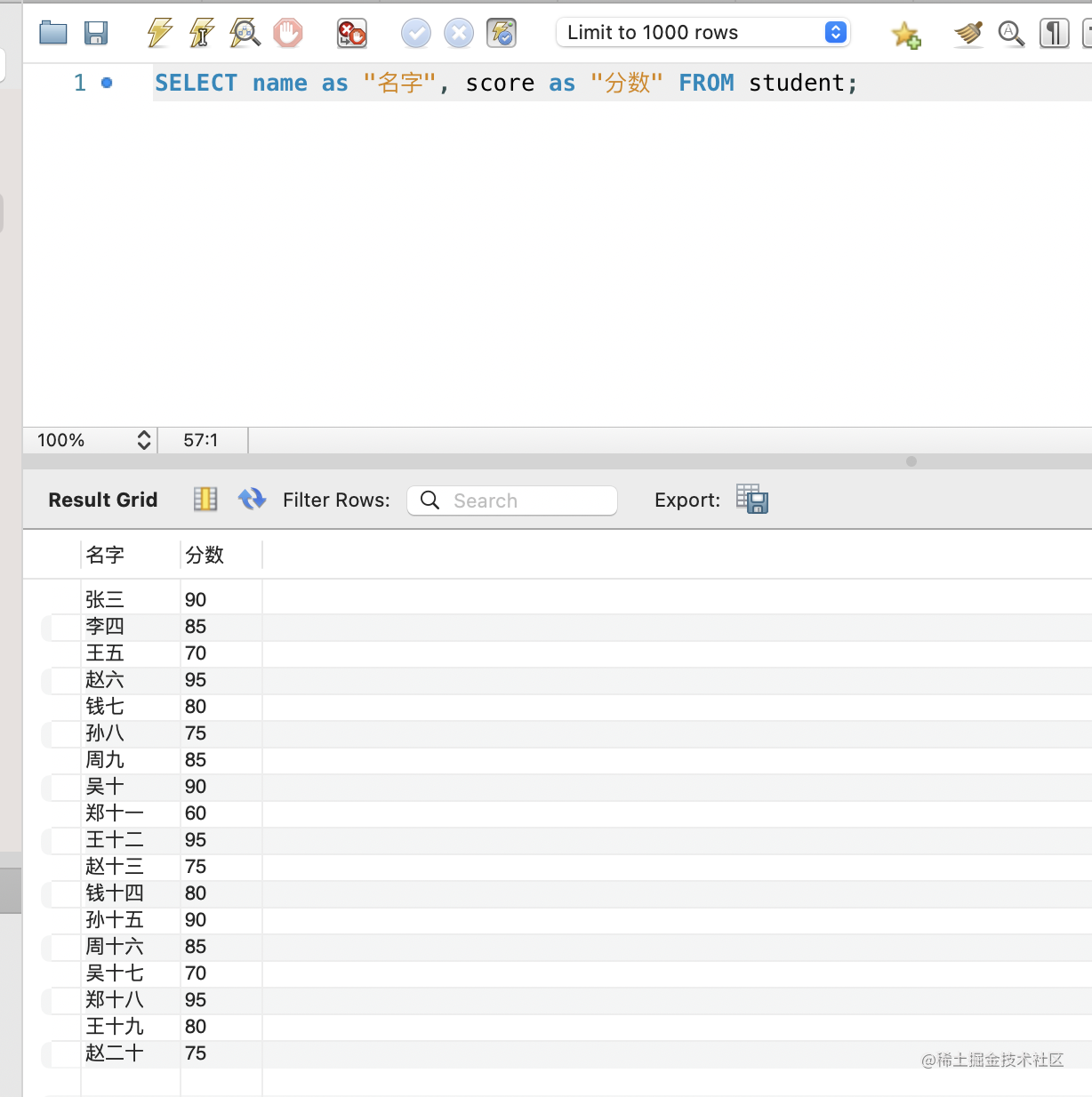
查询自然是可以带条件的,通过 where:
select name as 名字,class as 班级 from student where age >= 19;
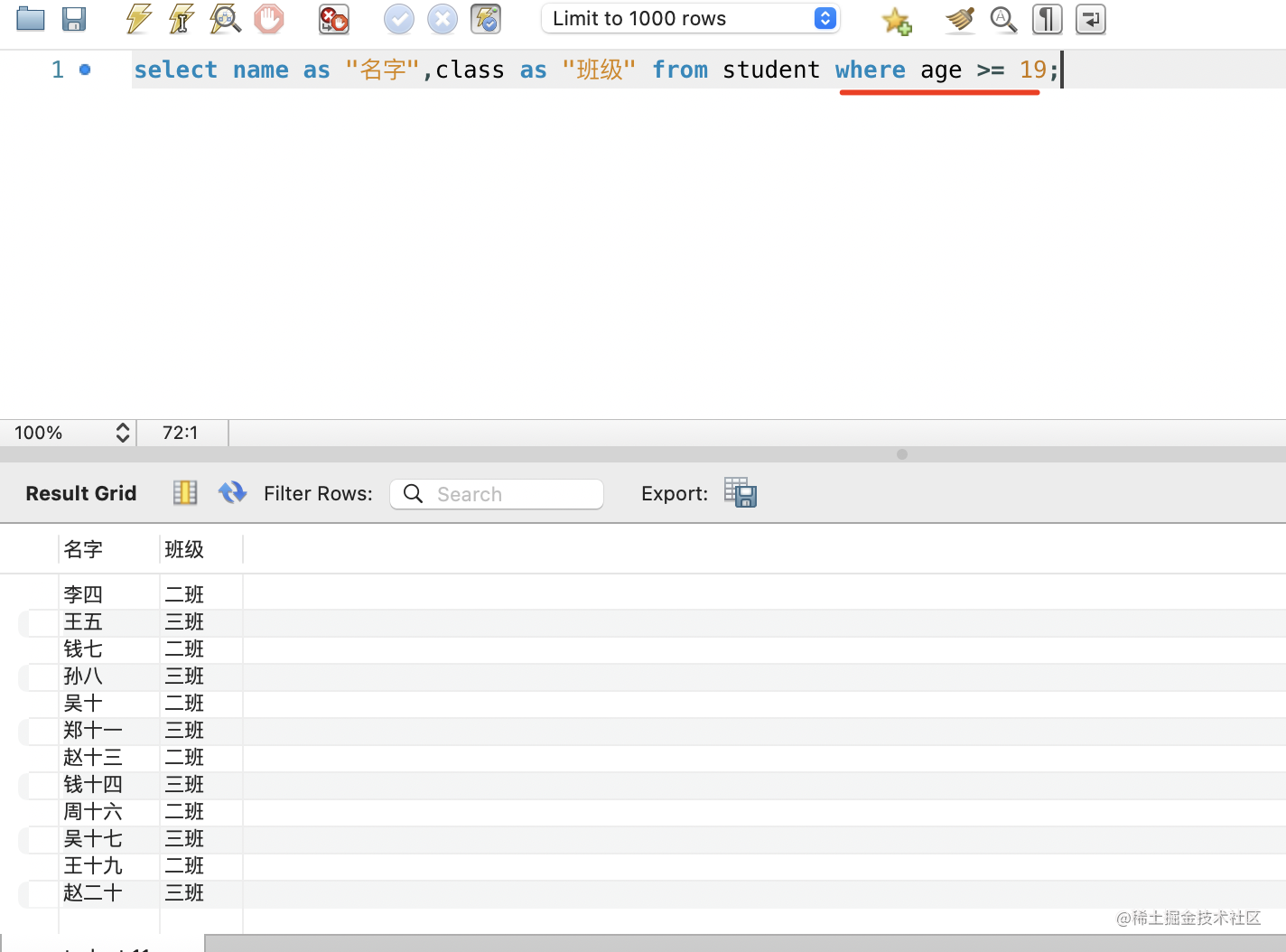
并且条件可以是 and 连接的多个:
select name as 名字,class as 班级 from student where gender='男' and score >= 90;
这里单双引号都可以。
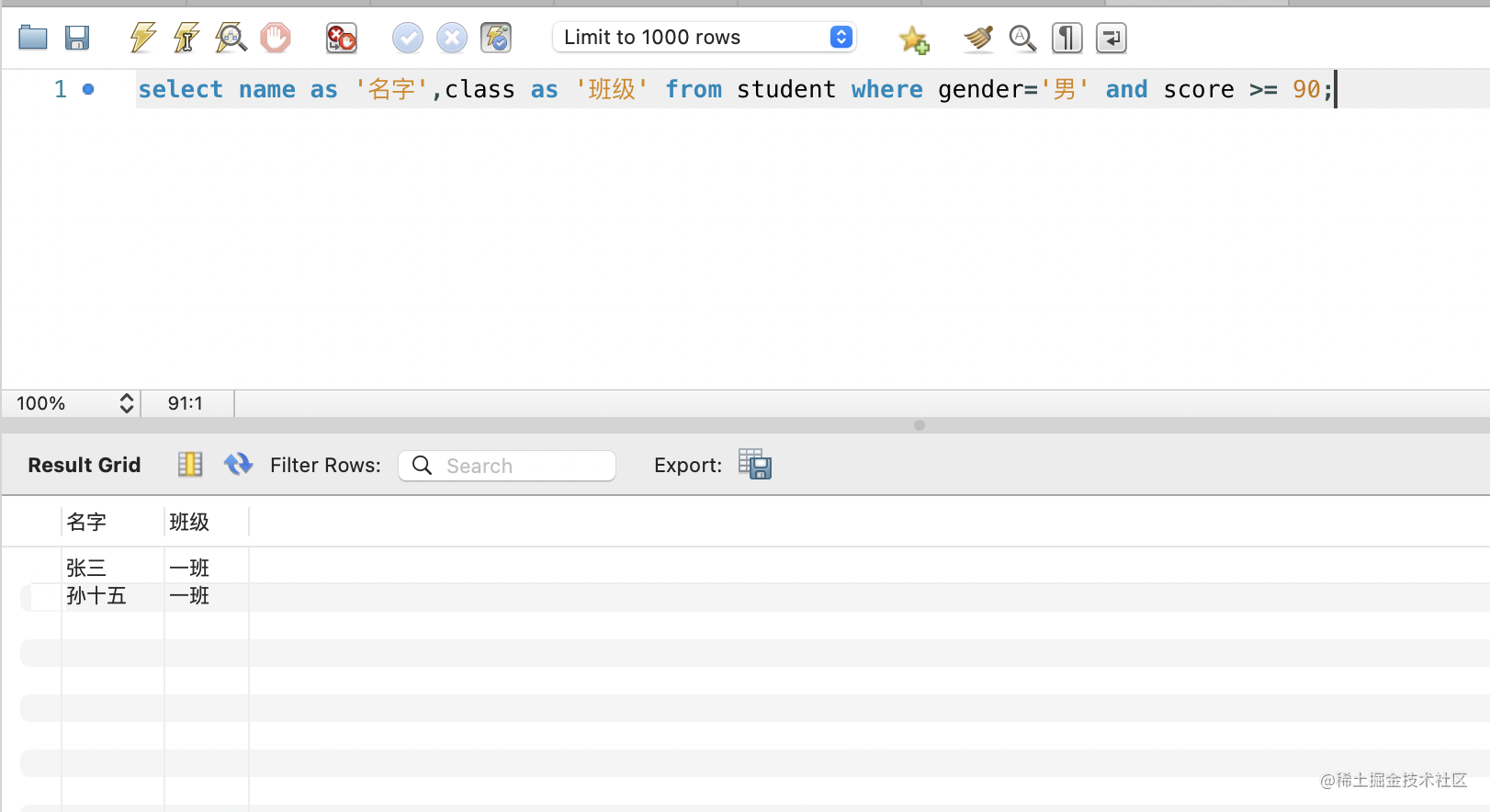
可以看到,有两个成绩在 90 以上的男生。
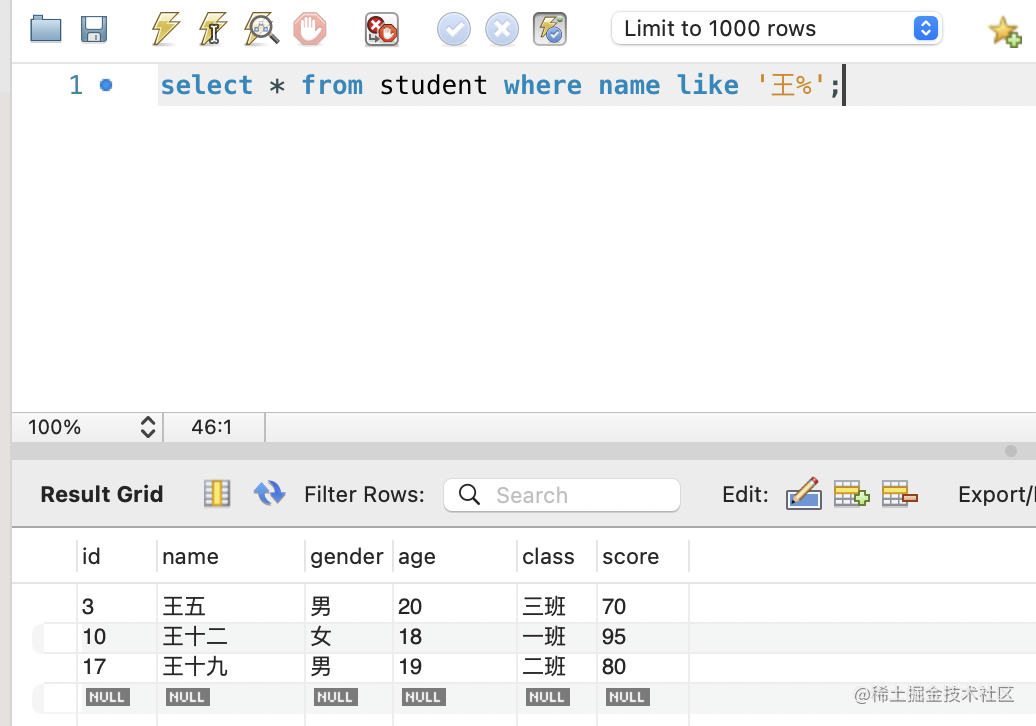
你还可以用 LIKE 做模糊查询。
比如查询名字以“王”开头的学生:
select * from student where name like '王%';
还可以通过 in 来指定一个集合:
select * from student where class in ('一班', '二班');
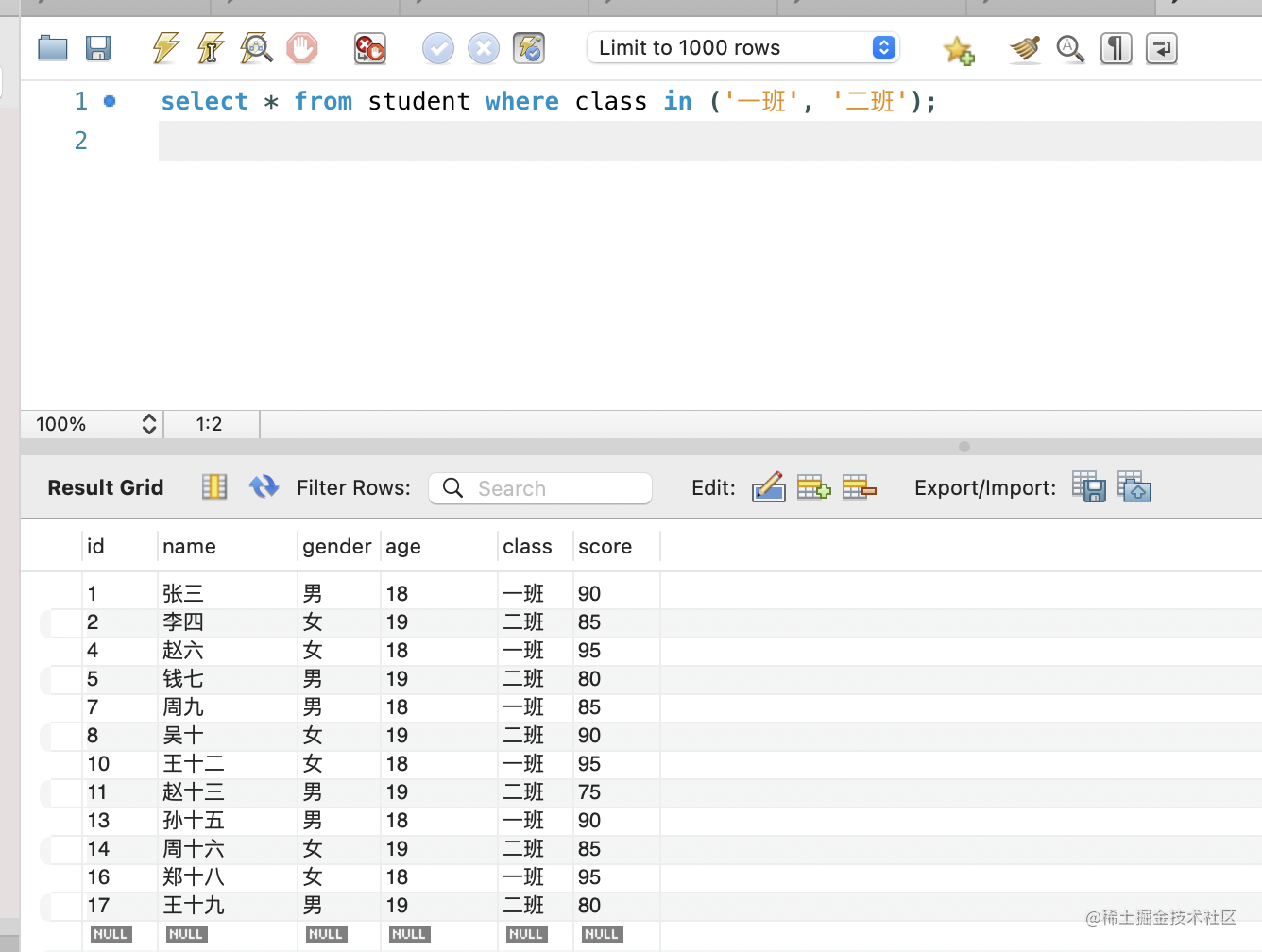
也可以 not in:
select * from student where class not in ('一班', '二班');
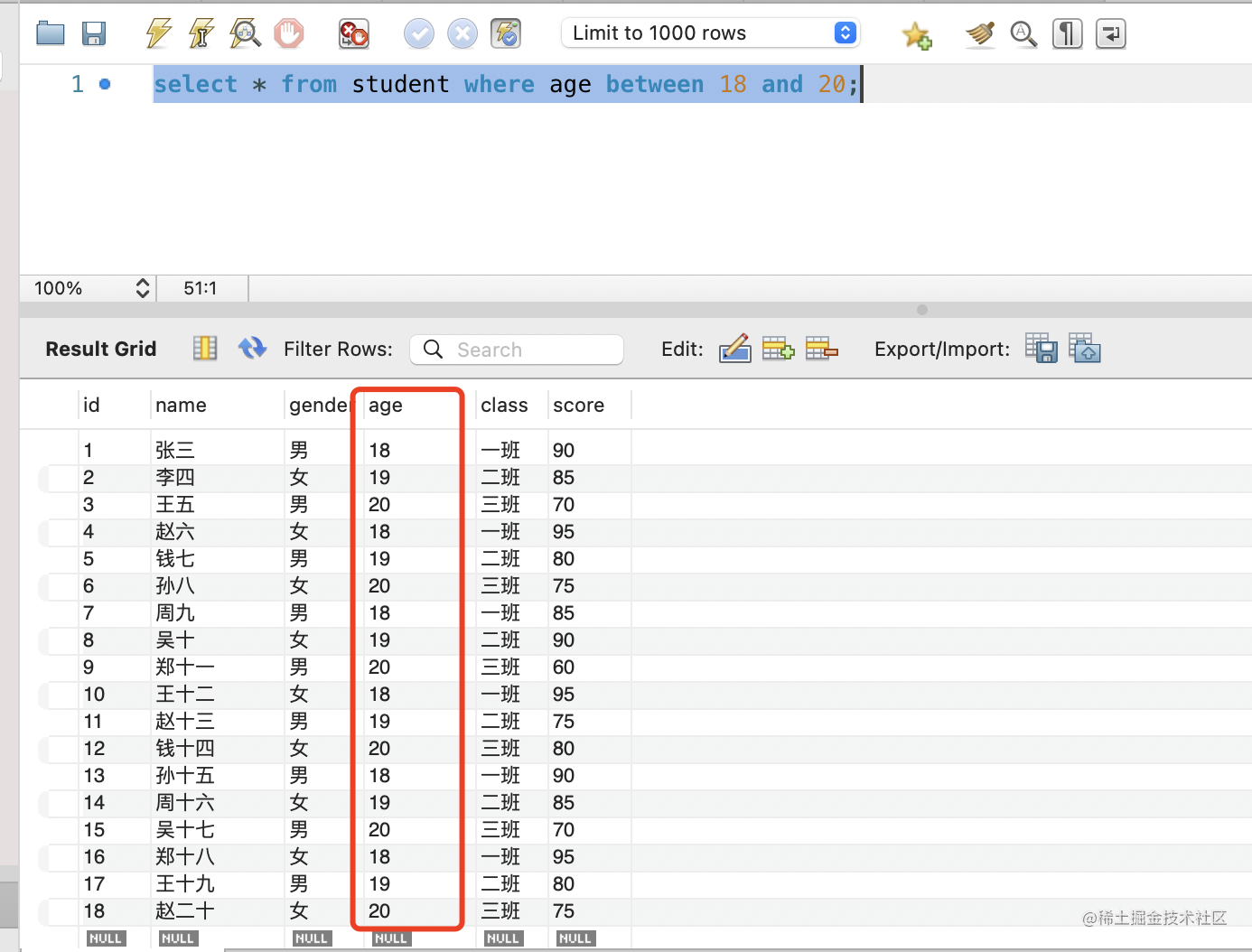
in 指定的是一个集合,还可以通过 between and 来指定一个区间:
select * from student where age between 18 and 20;
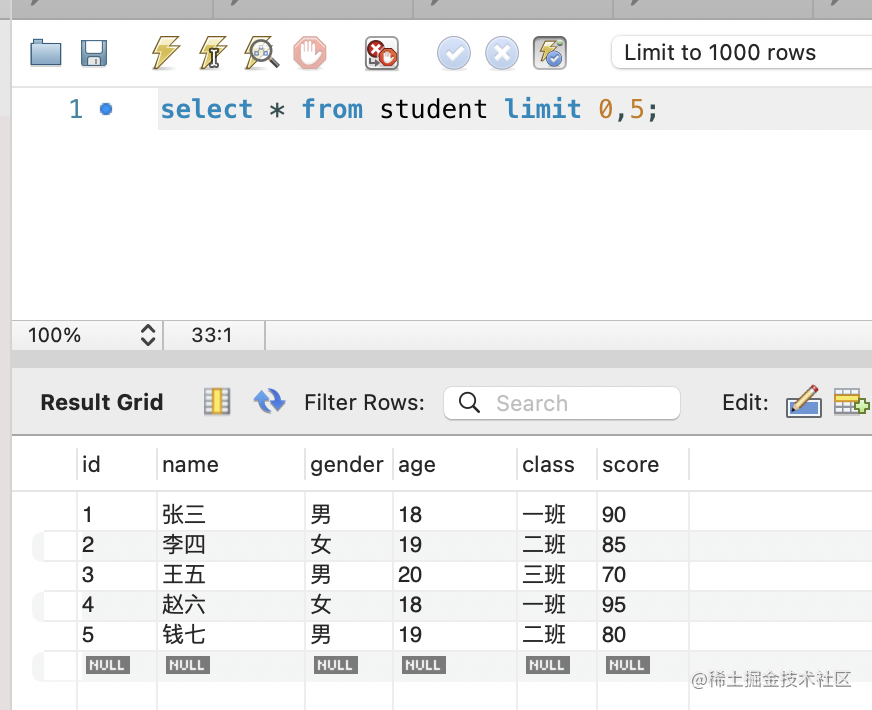
如果觉得返回的数量太多,可以分页返回,这个是通过 limit 实现的:
select * from student limit 0,5;
比如从 0 开始的 5 个:
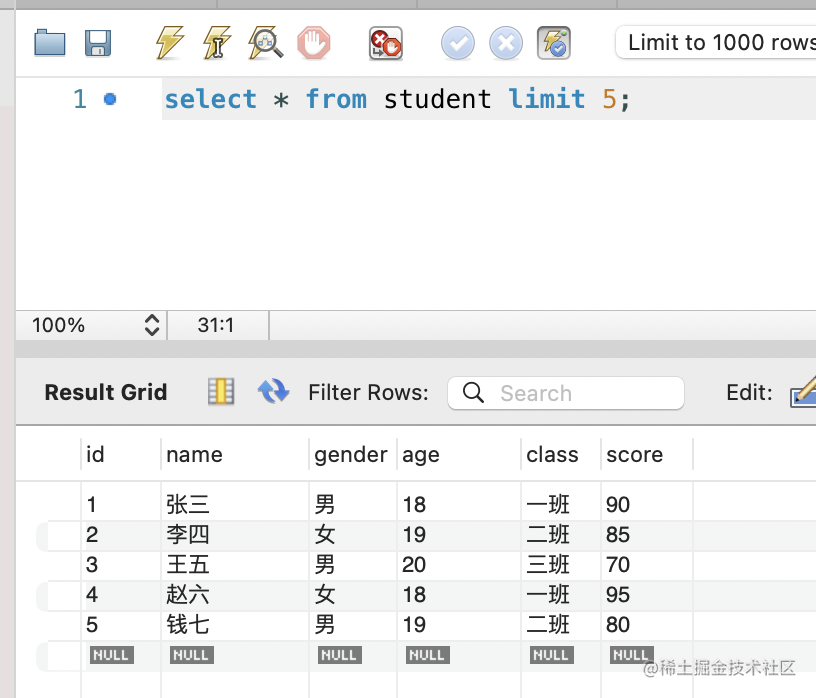
这种也可以简化为:
select * from student limit 5;
第二页的数据:
select * from student limit 5,5;
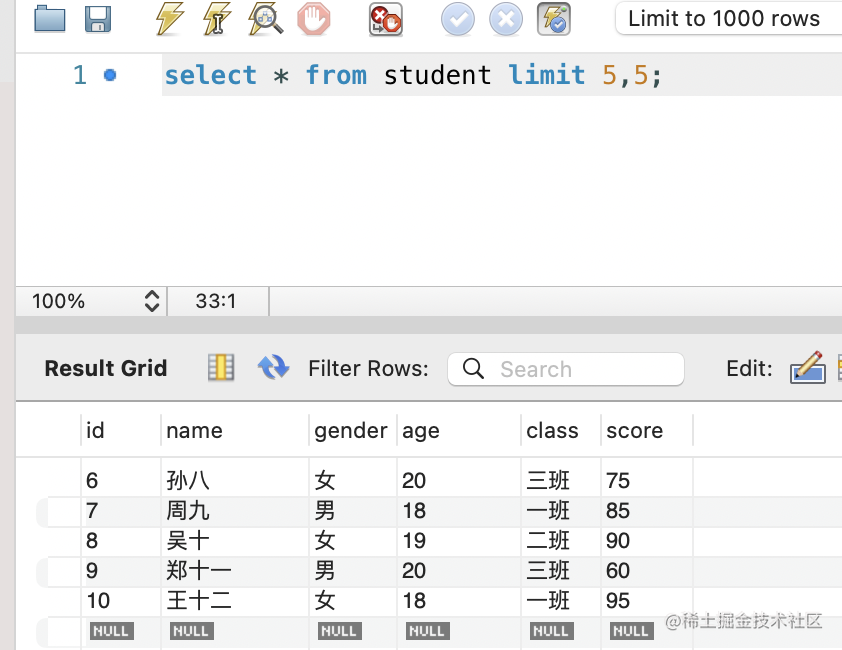
此外,你可以通过 order by 来指定排序的列:
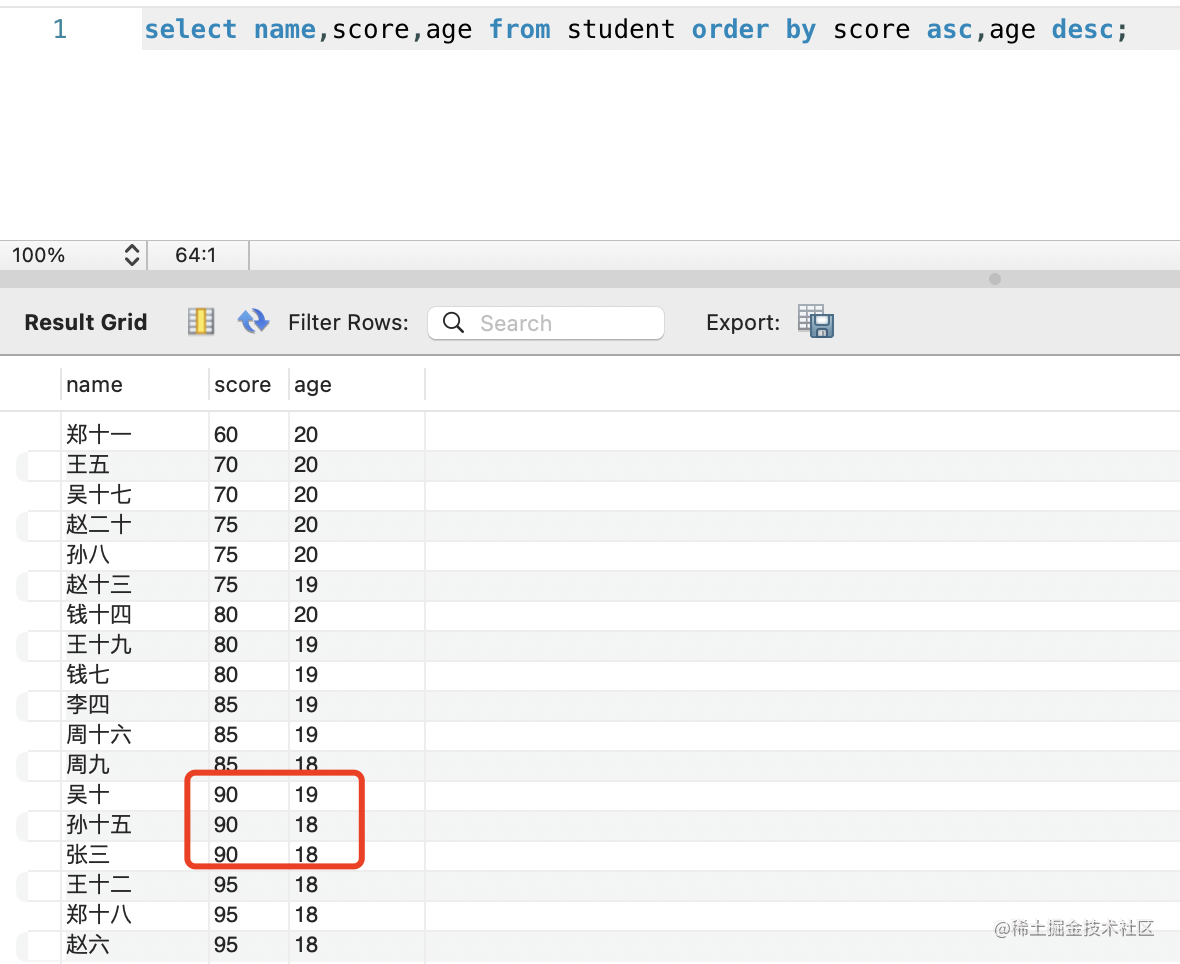
select name,score,age from student order by score asc,age desc;
order by 指定根据 score 升序排列,如果 score 相同再根据 age 降序排列。
此外,还可以分组统计。
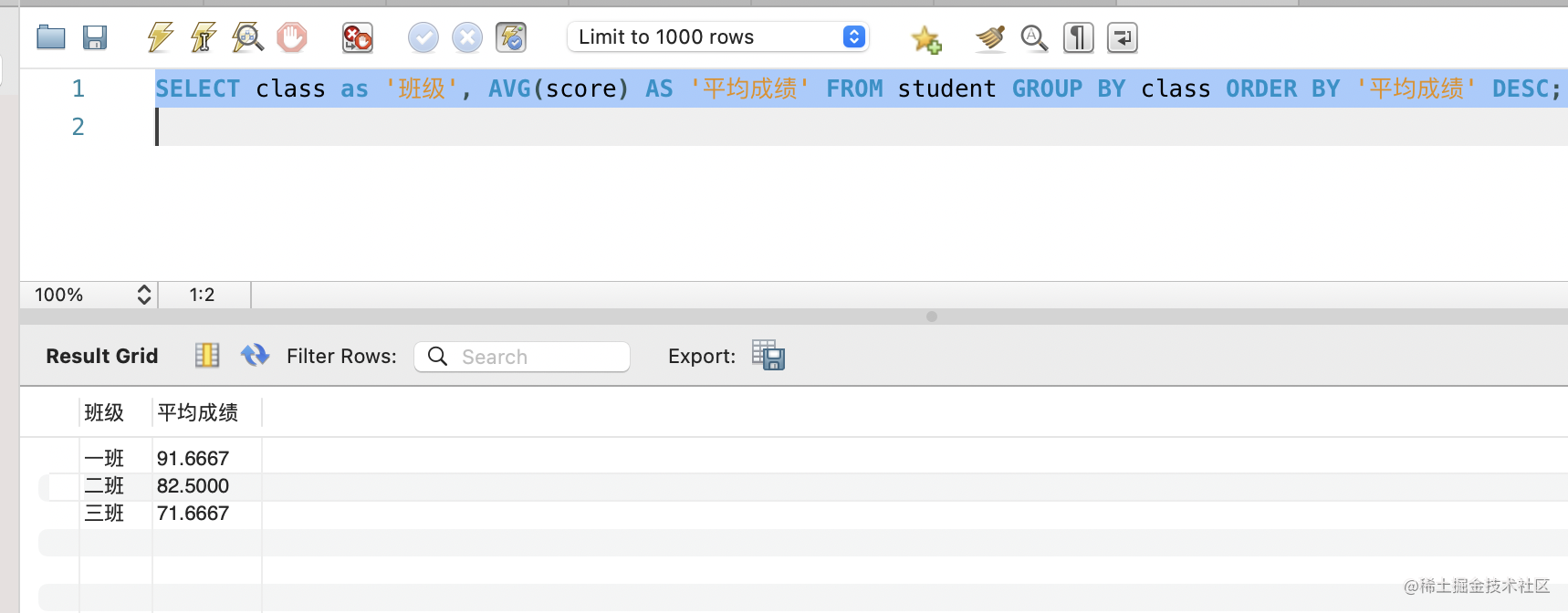
比如统计每个班级的平均成绩:
SELECT class as 班级, AVG(score) AS 平均成绩
FROM student
GROUP BY class
ORDER BY 平均成绩 DESC;
2
3
4
这里用到不少新语法:
根据班级来分组是 GROUP BY class。
求平均成绩使用 sql 内置的函数 AVG()。
之后根据平均成绩来降序排列。
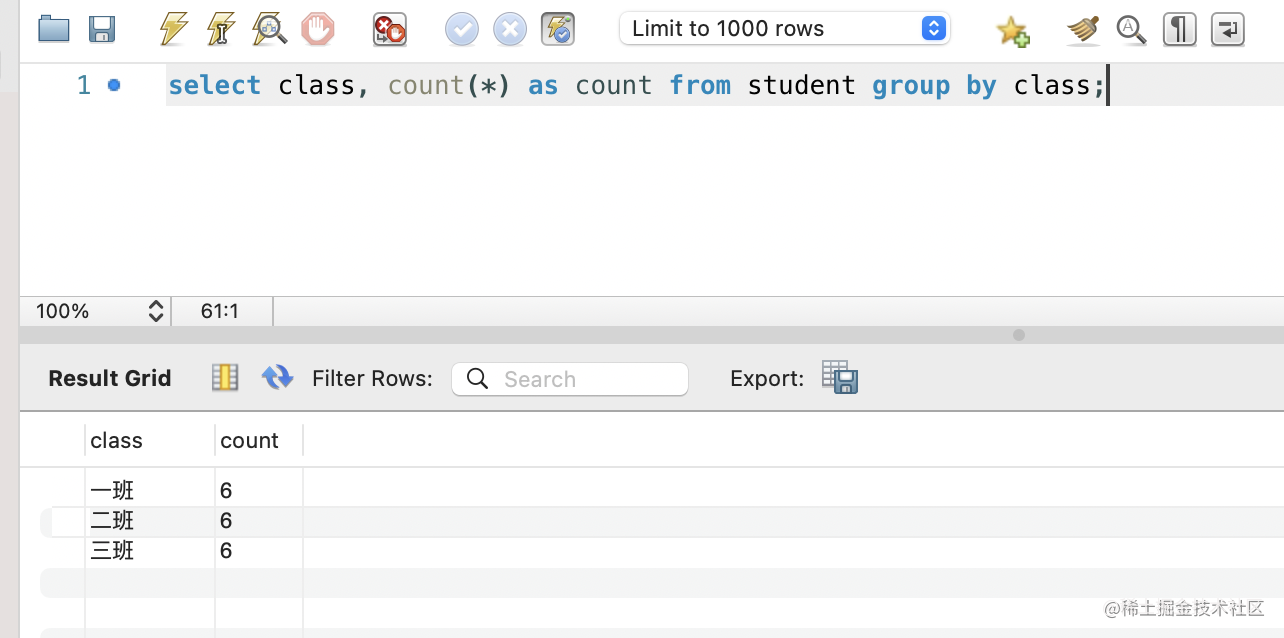
这种内置函数还有不少,比如 count:
select class, count(*) as count from student group by class;
这里的 * 就代表当前行。
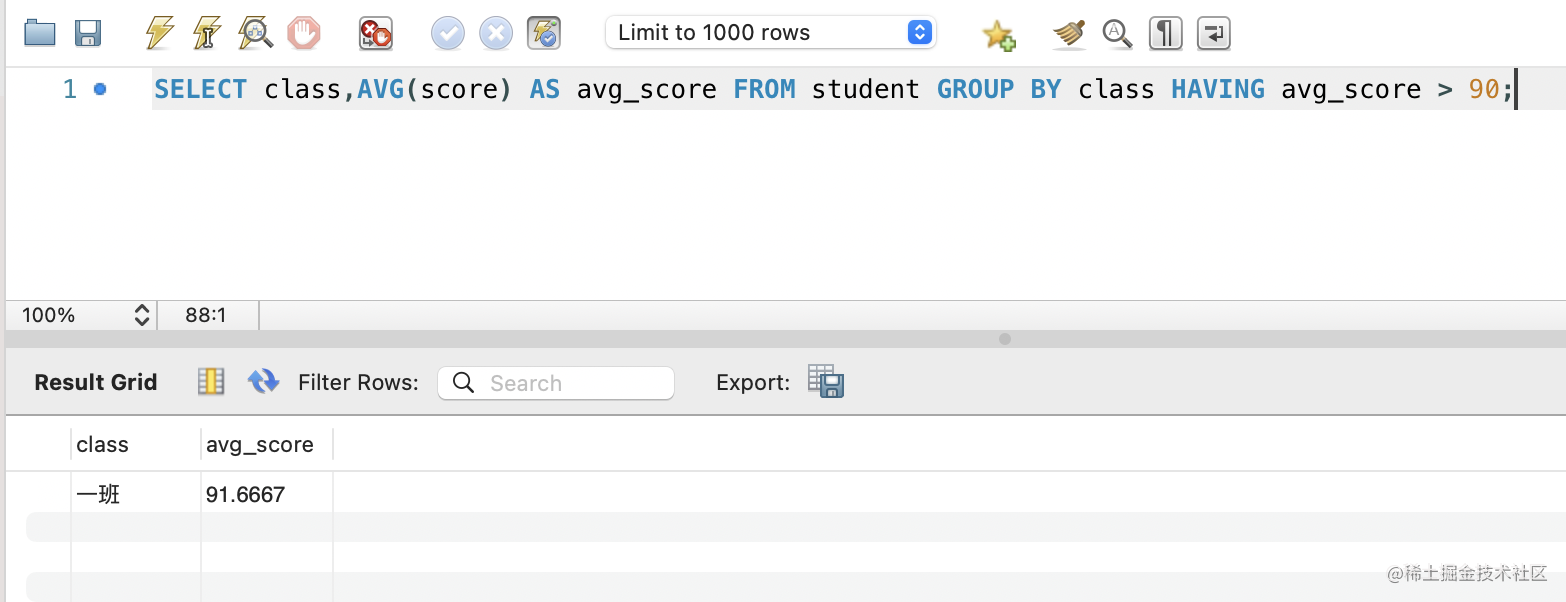
分组统计之后还可以做进一步的过滤,但这时候不是用 where 了,而是用 having:
SELECT class,AVG(score) AS avg_score
FROM student
GROUP BY class
HAVING avg_score > 90;
2
3
4
不过滤的时候是这样:
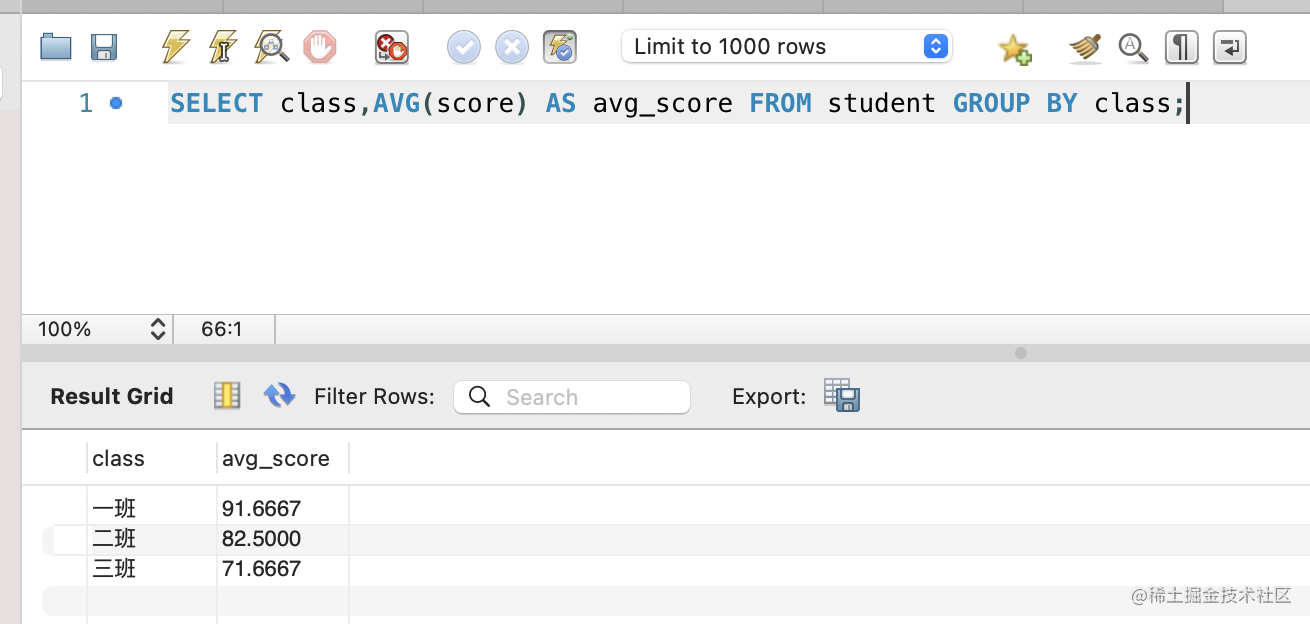
过滤之后是这样:
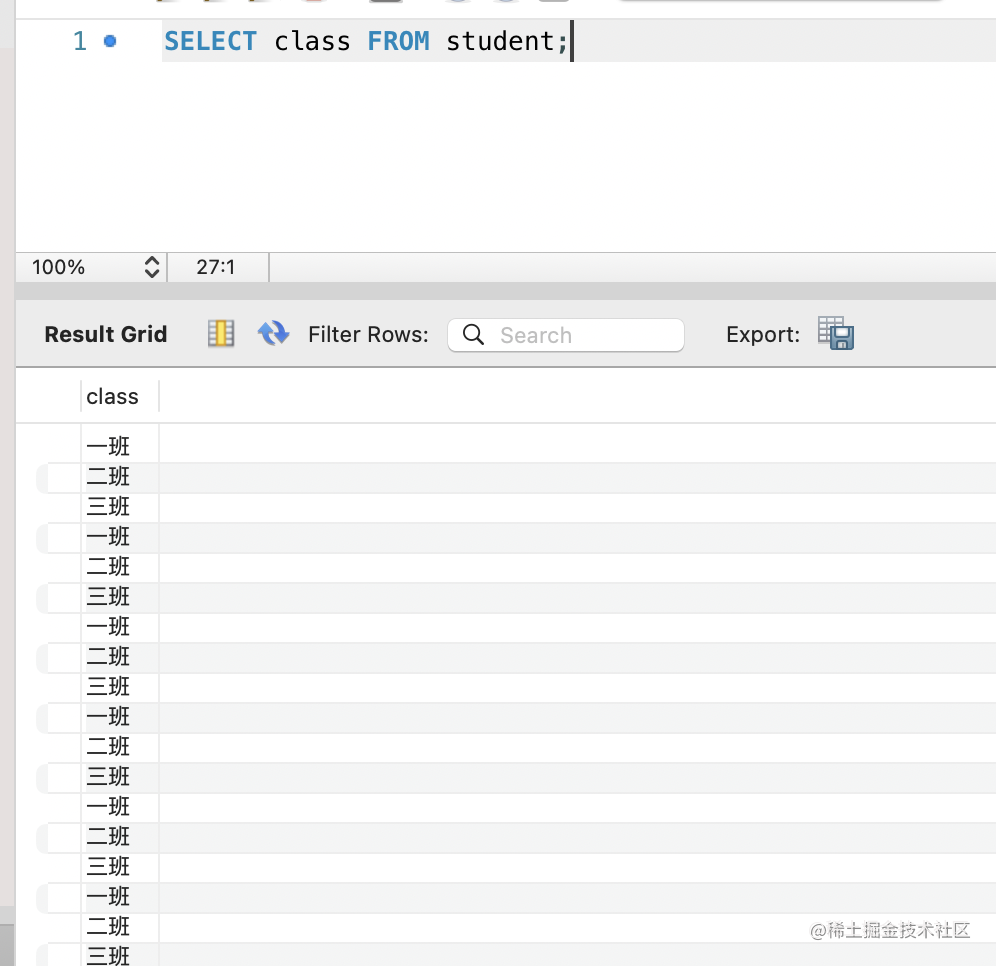
如果你想查看有哪些班级,可能会这样写:
SELECT class FROM student;
但这样会有很多重复的:
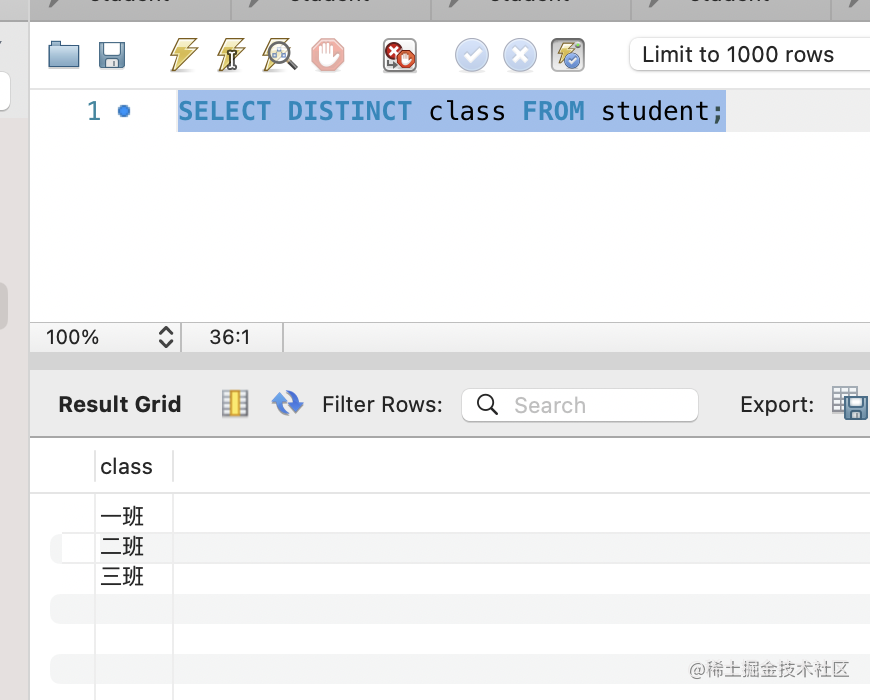
这时候可以用 distinct 去重:
最后再来过一遍所有的内置函数,函数分为这么几类:
# 内置函数
# 聚合函数:
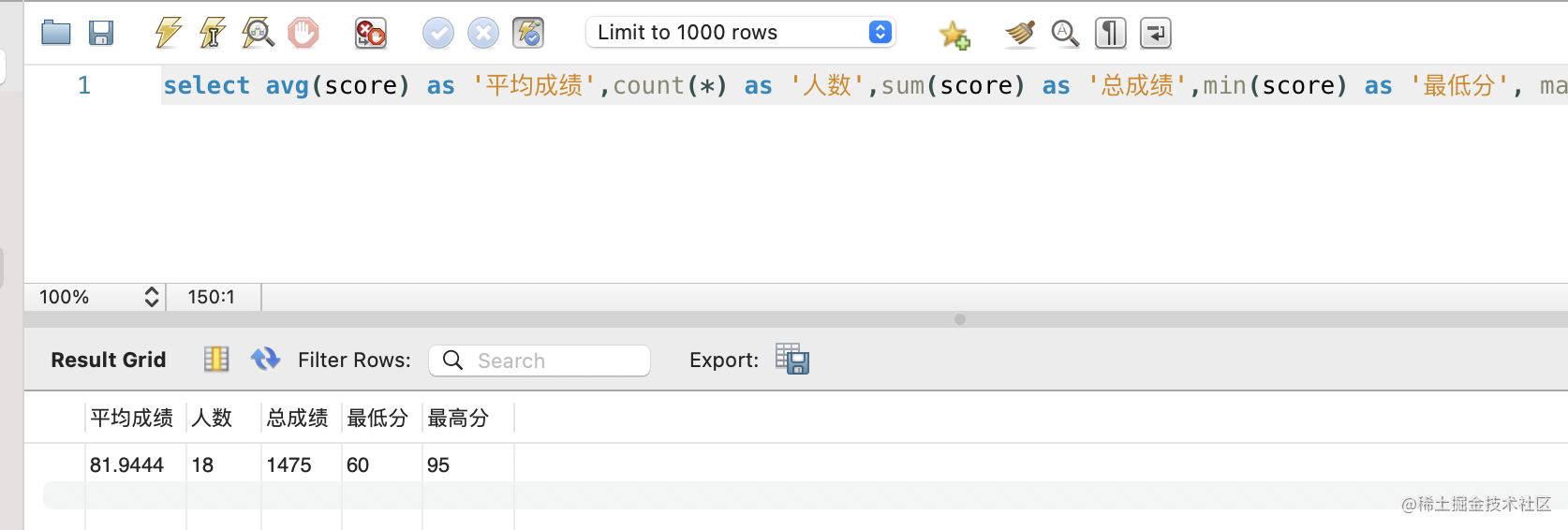
用于对数据的统计,比如 AVG、COUNT、SUM、MIN、MAX。
select avg(score) as 平均成绩,count(*) as 人数,sum(score) as 总成绩,min(score) as 最低分, max(score) as 最高分 from student
# 字符串函数:
用于对字符串的处理,比如 CONCAT、SUBSTR、LENGTH、UPPER、LOWER。
SELECT CONCAT('xx', name, 'yy'), SUBSTR(name,2,3), LENGTH(name), UPPER('aa'), LOWER('TT') FROM student;
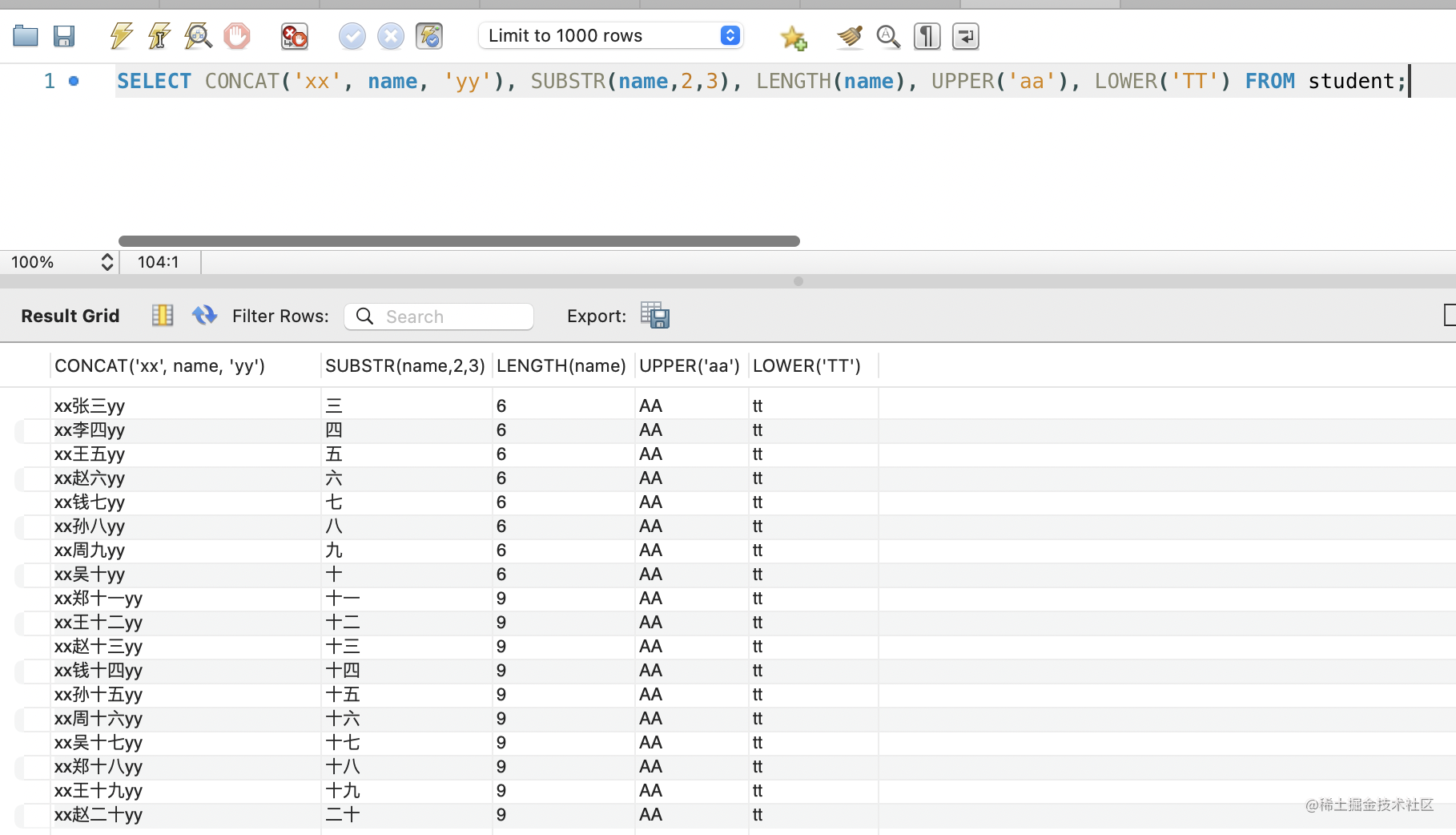
其中,substr 第二个参数表示开始的下标(mysql 下标从 1 开始),所以 substr('一二三',2,3) 的结果是 '二三'。
当然,也可以不写结束下标 substr('一二三',2)
# 数值函数:
用于对数值的处理,比如 ROUND、CEIL、FLOOR、ABS、MOD。
SELECT ROUND(1.234567, 2), CEIL(1.234567), FLOOR(1.234567), ABS(-1.234567), MOD(5, 2);
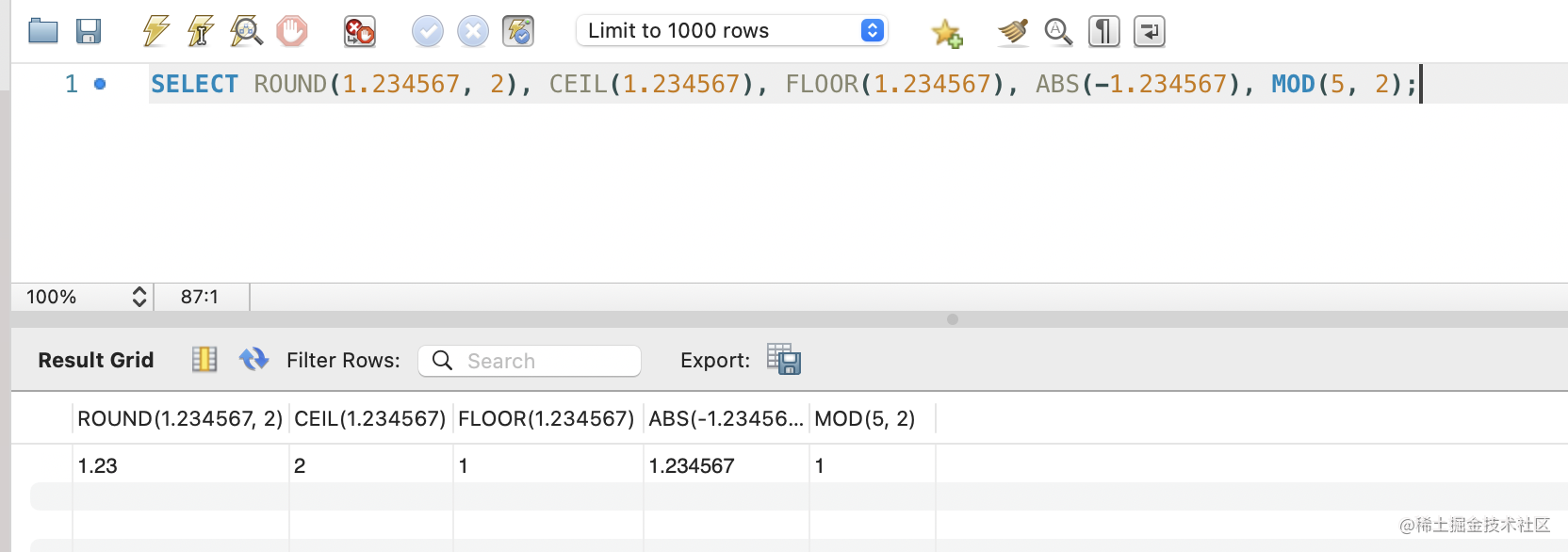
分别是 ROUND 四舍五入、CEIL 向上取整、FLOOR 向下取整、ABS 绝对值、MOD 取模。
# 日期函数:
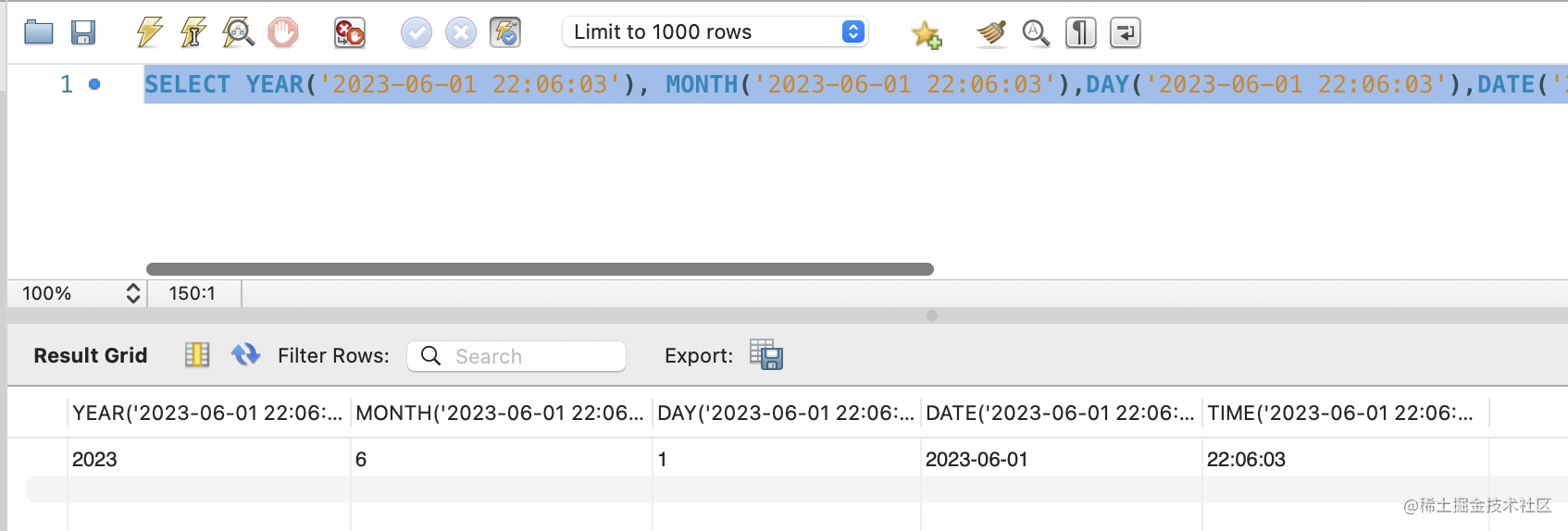
对日期、时间进行处理,比如 DATE、TIME、YEAR、MONTH、DAY
SELECT YEAR('2023-06-01 22:06:03'), MONTH('2023-06-01 22:06:03'),DAY('2023-06-01 22:06:03'),DATE('2023-06-01 22:06:03'), TIME('2023-06-01 22:06:03');
# 条件函数:
根据条件是否成立返回不同的值,比如 IF、CASE
select name, if(score >=60, '及格', '不及格') from student;
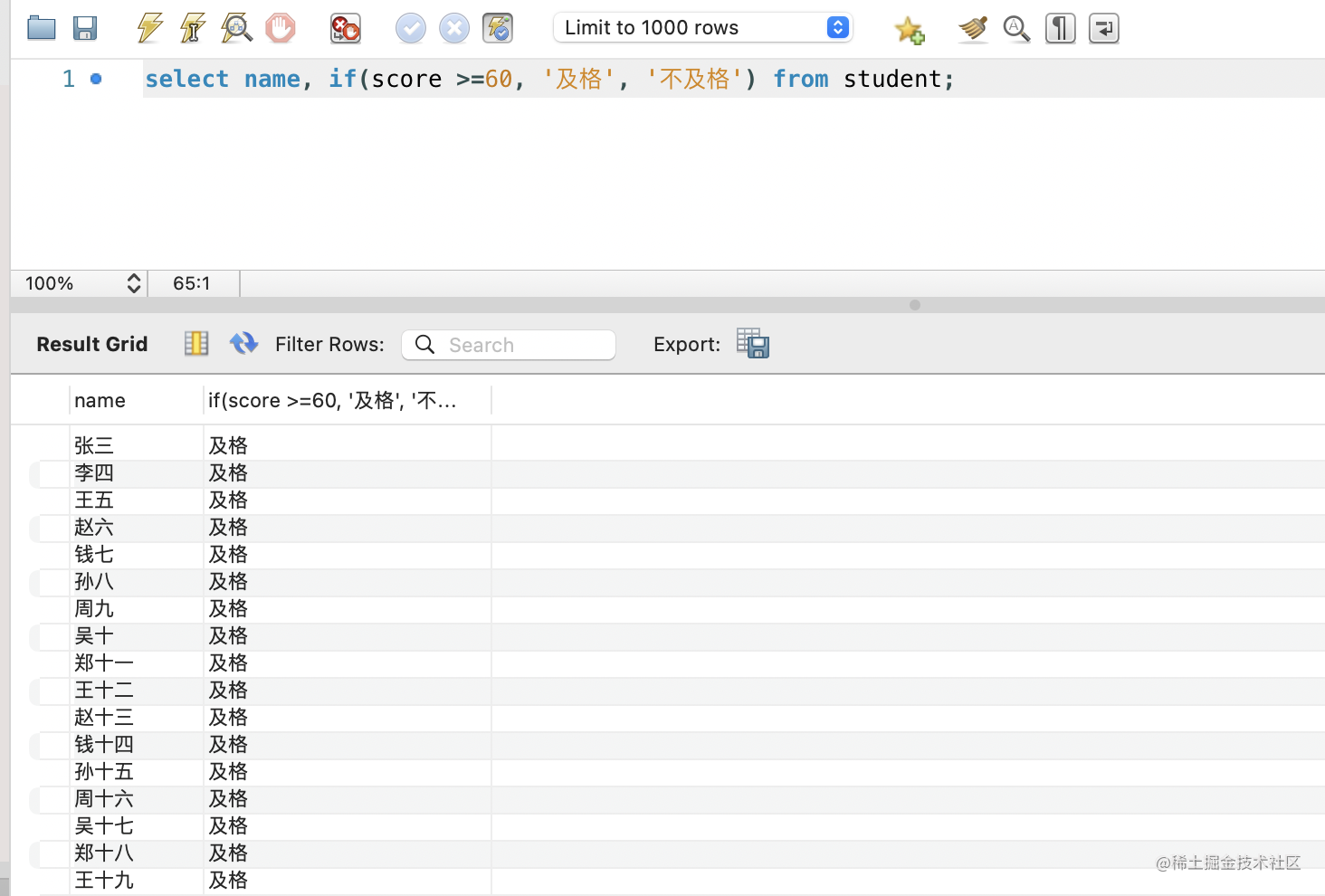
SELECT name, score, CASE WHEN score >=90 THEN '优秀' WHEN score >=60 THEN '良好'ELSE '差' END AS '档次' FROM student;
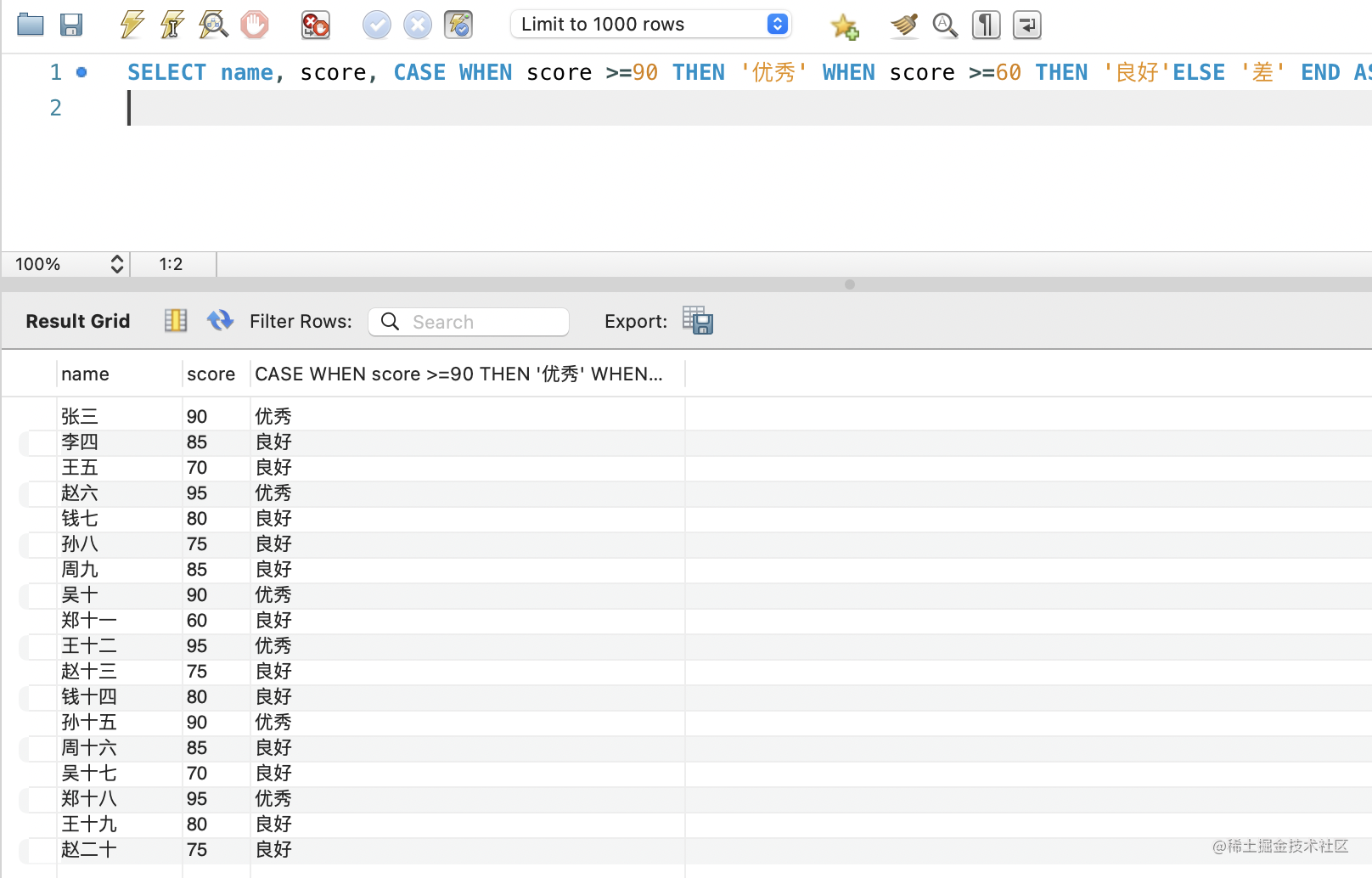
if 和 case 函数和 js 里的 if、swtch 语句很像,很容易理解。
if 函数适合单个条件,case 适合多个条件。
# 系统函数:
用于获取系统信息,比如 VERSION、DATABASE、USER。
select VERSION(), DATABASE(), USER()
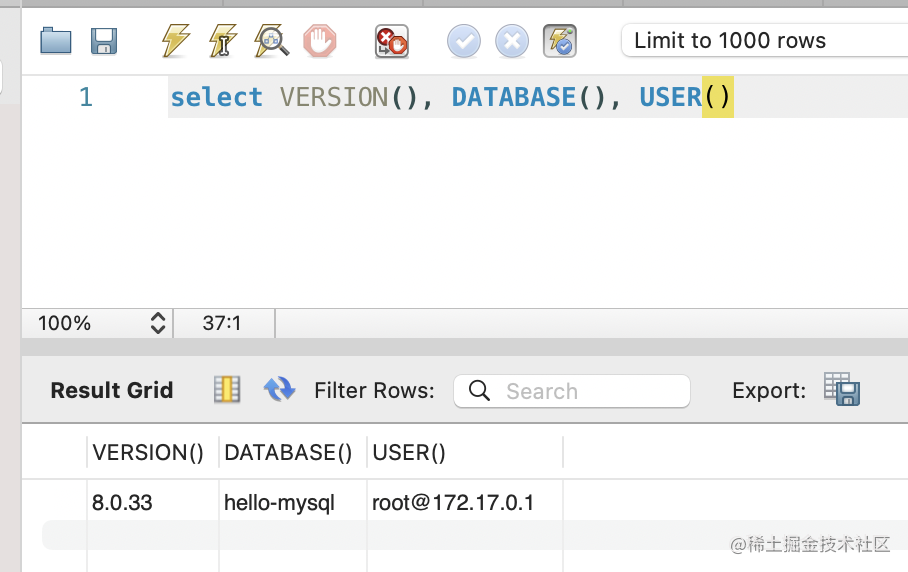
# 其他函数:
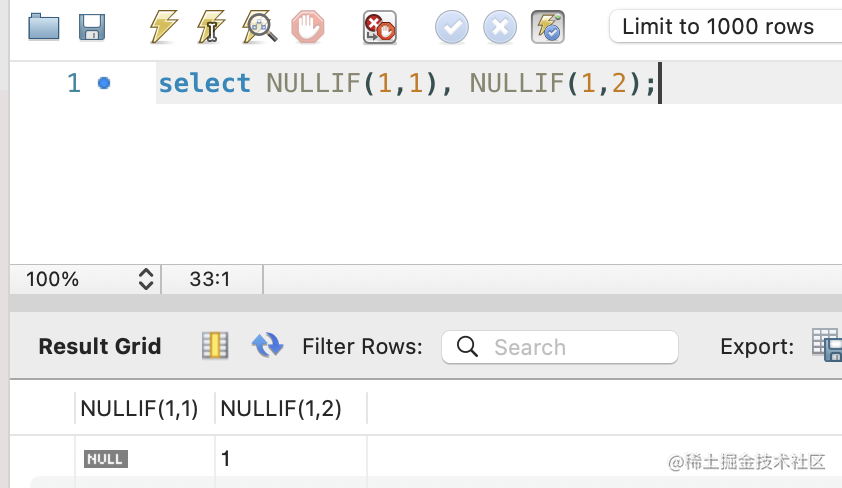
NULLIF、COALESCE、GREATEST、LEAST。
NULLIF:如果相等返回 null,不相等返回第一个值。
select NULLIF(1,1), NULLIF(1,2);
COALESCE:返回第一个非 null 的值:
select COALESCE(null, 1), COALESCE(null, null, 2)
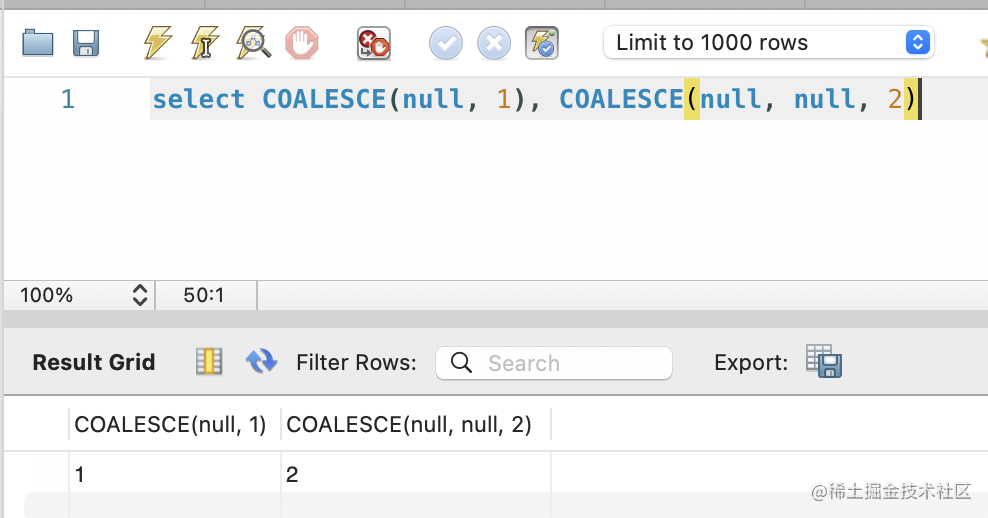
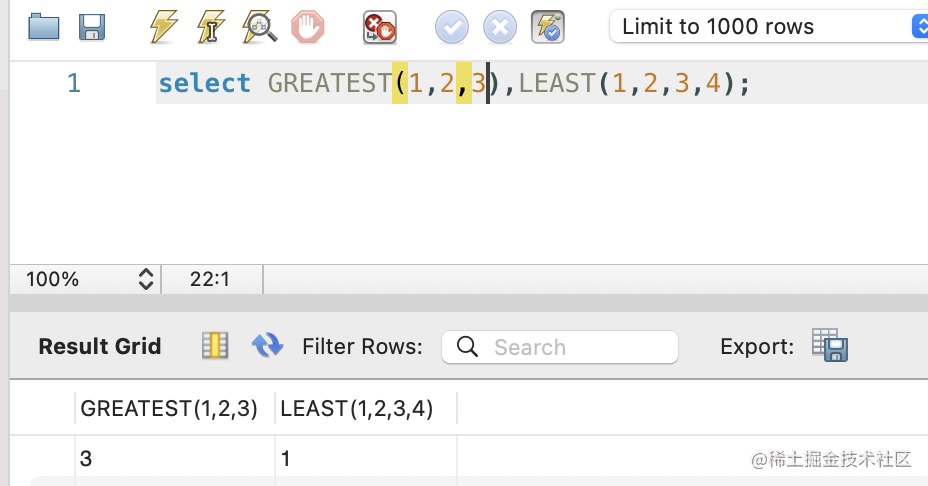
GREATEST、LEAST:返回几个值中最大最小的。
select GREATEST(1,2,3),LEAST(1,2,3,4);
# 类型转换函数:
转换类型为另一种,比如 CAST、CONVERT、DATE_FORMAT、STR_TO_DATE。
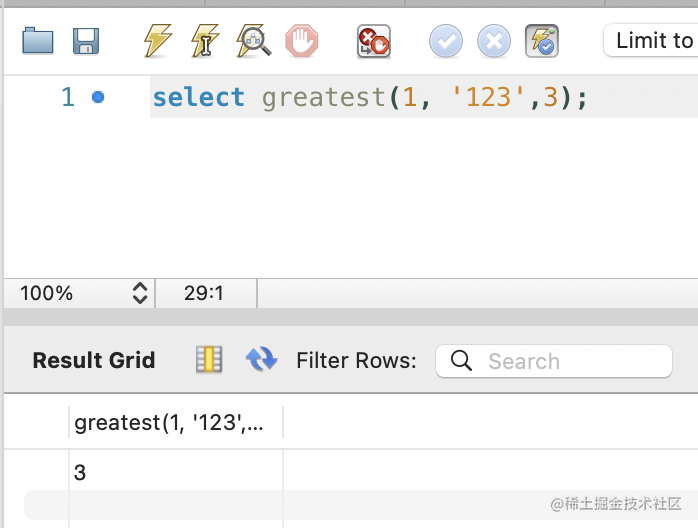
比如下面的函数:
select greatest(1, '123',3);
3 最大,因为它并没有把 '123' 当成数字
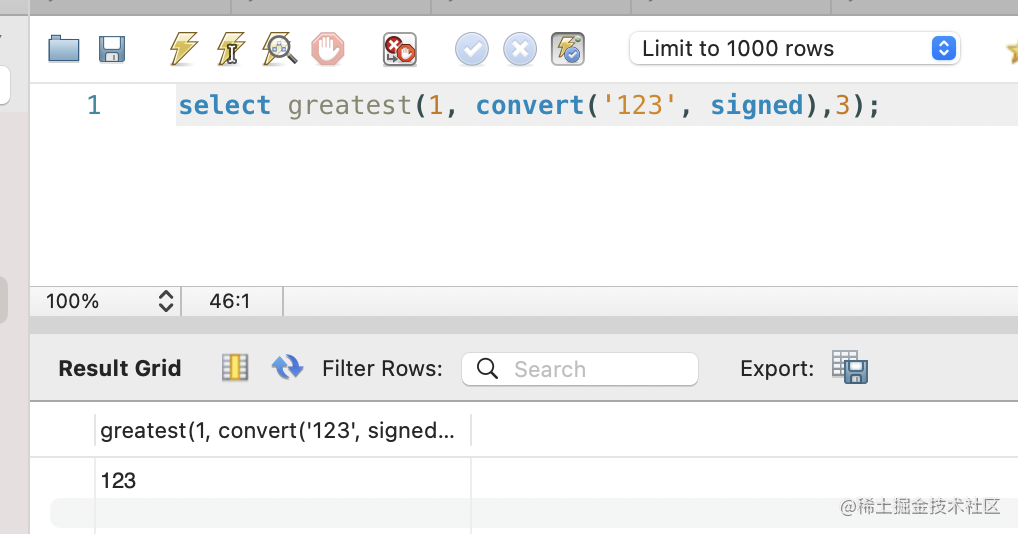
这时候就可以用 convert 或者 cast 做类型转换了:
select greatest(1, convert('123', signed),3);
select greatest(1, cast('123' as signed),3);
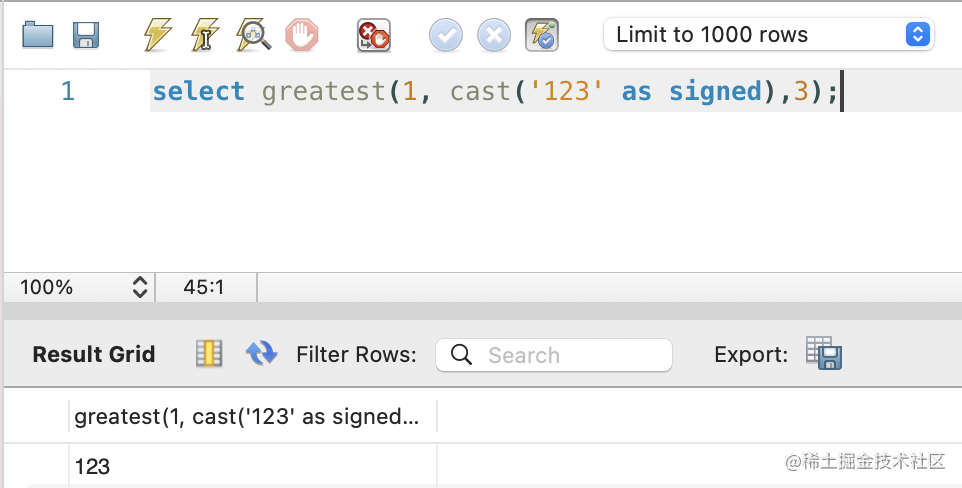
这里可以转换的类型有这些:
- signed:整型;
- unsigned:无符号整型
- decimal:浮点型;
- char:字符类型;
- date:日期类型;
- time:时间类型;
- datetime:日期时间类型;
- binary:二进制类型
剩下的 STR_TO_DATE 和 DATE_FORMAT 还是很容易理解的:
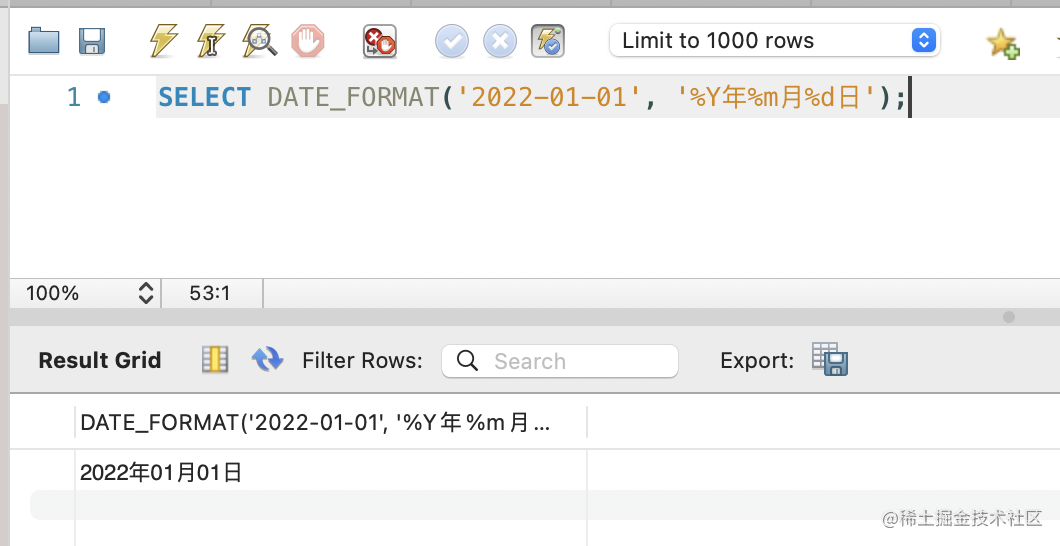
SELECT DATE_FORMAT('2022-01-01', '%Y年%m月%d日');
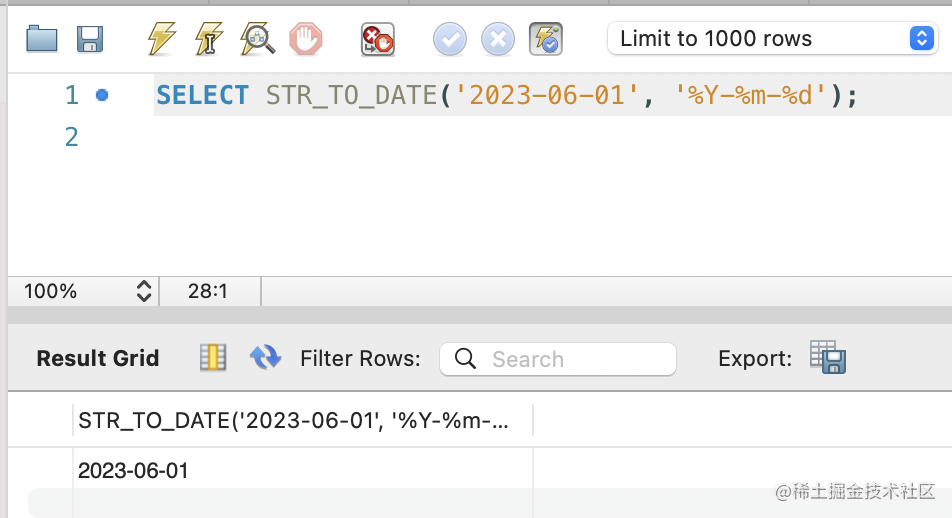
SELECT STR_TO_DATE('2023-06-01', '%Y-%m-%d');
至此,我们就把 sql 查询的语法和函数都过了一遍。
此外,你可能注意到,写 sql 的时候,我们有的时候用单双引号,有的时候用反引号,有的时候不加引号:


这里要注意下,当作字符串值用的时候,需要加单引号或者双引号。当作表名、列名用的时候,用反引号或者不加引号。
# 总结
我们连接 mysql 数据库,建了张 student 表,插入了一些数据,然后用这些数据来练习了各种查询语法和函数。
- where:查询条件,比如 where id=1
- as:别名,比如 select xxx as 'yyy'
- and: 连接多个条件
- in/not in:集合查找,比如 where a in (1,2)
- between and:区间查找,比如 where a between 1 and 10
- limit:分页,比如 limit 0,5
- order by:排序,可以指定先根据什么升序、如果相等再根据什么降序,比如 order by a desc,b asc
- group by:分组,比如 group by aaa
- having:分组之后再过滤,比如 group by aaa having xxx > 5
- distinct:去重
sql 还可以用很多内置函数:
- 聚合函数:avg、count、sum、min、max
- 字符串函数:concat、substr、length、upper、lower
- 数值函数:round、ceil、floor、abs、mod
- 日期函数:year、month、day、date、time
- 条件函数:if、case
- 系统函数:version、datebase、user
- 类型转换函数:convert、cast、date_format、str_to_date
- 其他函数:nullif、coalesce、greatest、least
灵活掌握这些语法,就能写出各种复杂的查询语句。