
 Docker 是怎么实现的
Docker 是怎么实现的# Docker 是怎么实现的
前面我们学习了 Docker 镜像、容器的各种操作,dockerfile 的编写,dockerignore 和镜像的多阶段构建。
是不是感觉 Docker 也没多少东西?
确实,Docker 用起来还是很简单的,学习成本不高。
那它是怎么实现的呢?
# Docker 容器跑起来就像一个独立的系统一样,它是怎么做到的?
如果网页上有两份 aaa、bbb 变量,我们怎么保证它们不冲突呢?
namespace 呀:
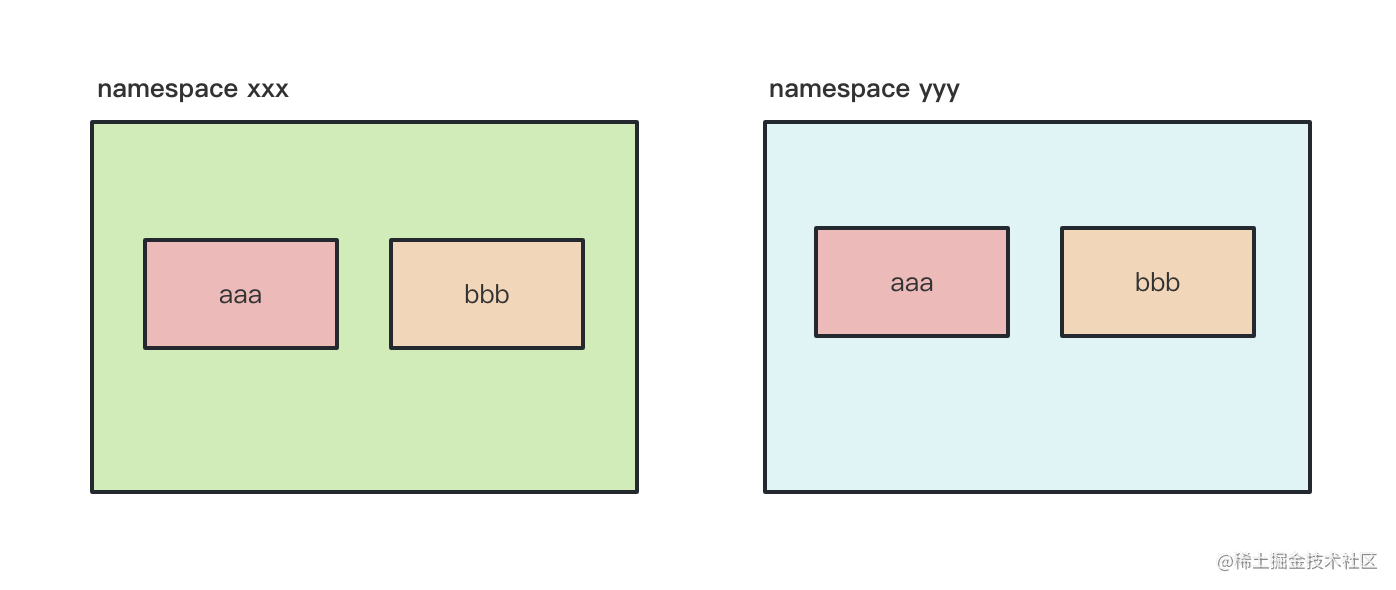
变成 xxx.aaa、xxx.bbb 和 yyy.aaa、yyy.bbb 就不冲突了。
Docker 在一个操作系统上实现多个独立的容器也是这种思路。
linux 操作系统提供了 namespace 机制,可以给进程、用户、网络等分配一个命名空间,这个命名空间下的资源都是独立命名的。
比如 PID namespace,也就是进程的命名空间,所有进程都是在命名空间内独立分配 id 的。
而 IPC namespace 能限制只有这个 namespace 内的进程可以相互通信,不能和 namespace 外的进程通信。
Mount namespace 会创建一个新的文件系统,namespace 内的文件访问都是在这个文件系统之上。
类似这样的 namespace 一共有 6 种:
- PID namespace: 进程 id 的命名空间
- IPC namespace: 进程通信的命名空间
- Mount namespace:文件系统挂载的命名空间
- Network namespace:网络的命名空间
- User namespace:用户和用户组的命名空间
- UTS namespace:主机名和域名的命名空间
通过这 6 种命名空间,Docker 就实现了独立的容器,在容器内运行的代码就像在一个独立的系统里跑一样。
但是只有命名空间的隔离还不够,还得对资源做限制。
比如一个容器占用了太多的资源,那就会导致别的容器受影响。
# 怎么能限制容器的资源访问呢?
这就需要 linux 操作系统的另一种机制:Control Group。
创建一个 Control Group 可以给它指定参数,比如 cpu 用多少、内存用多少、磁盘用多少,然后加到这个组里的进程就会受到这个限制。
这样,创建容器的时候先创建一个 Control Group,指定资源的限制,然后把容器进程加到这个 Control Group 里,就不会有容器占用过多资源的问题了。
那这样就完美了么?
其实还有一个问题:每个容器都是独立的文件系统,相互独立,而这些文件系统之间可能很大部分都是一样的,同样的内容占据了很大的磁盘空间,会导致浪费。
所以 Docker 设计了一种分层机制:
每一层都是不可修改的,也叫做镜像。
要修改就创建个新的层:
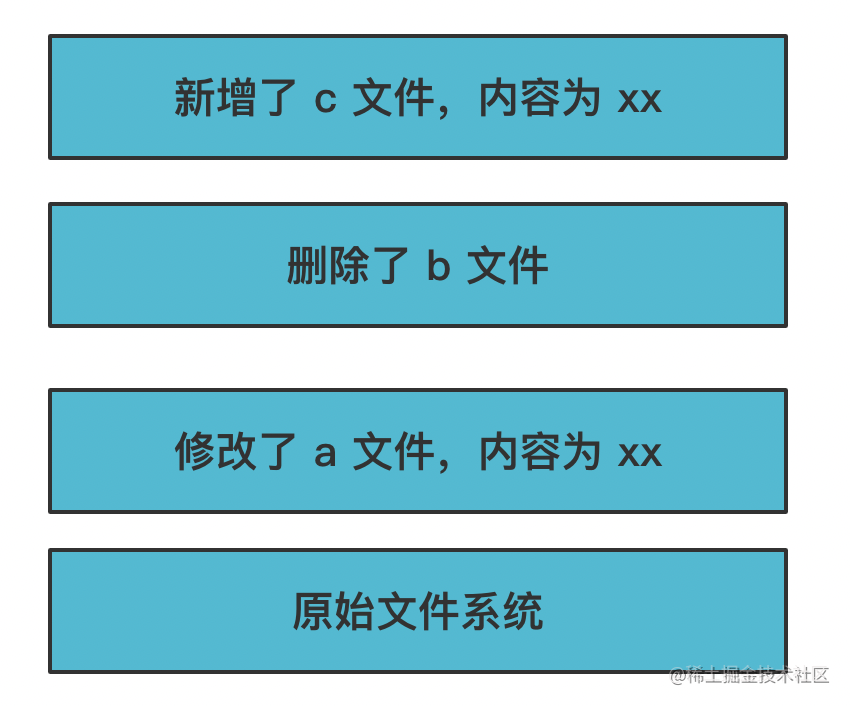
然后通过一种叫做 UnionFS 的机制把这些层合并起来,变成一个文件系统:
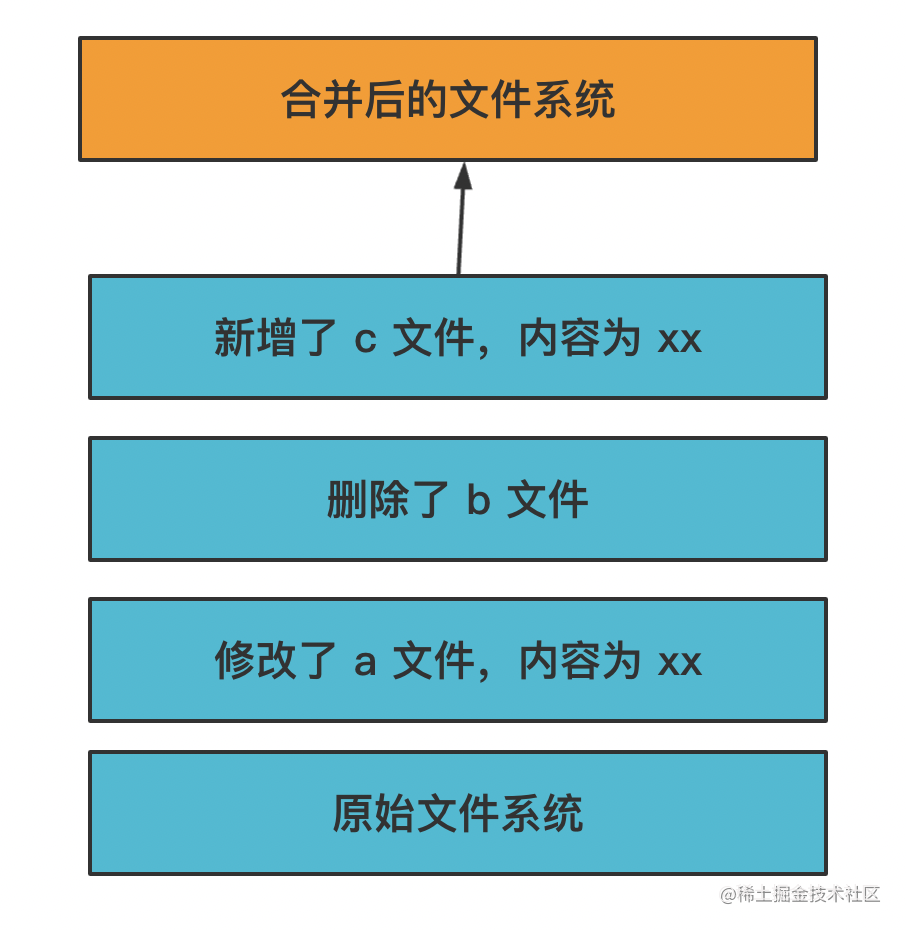
这样如果有多个容器内做了文件修改,只要创建不同的层即可,底层的基础镜像是一样的。
我们写的这个 Dockerfile,每一行指令都会生成一层镜像:
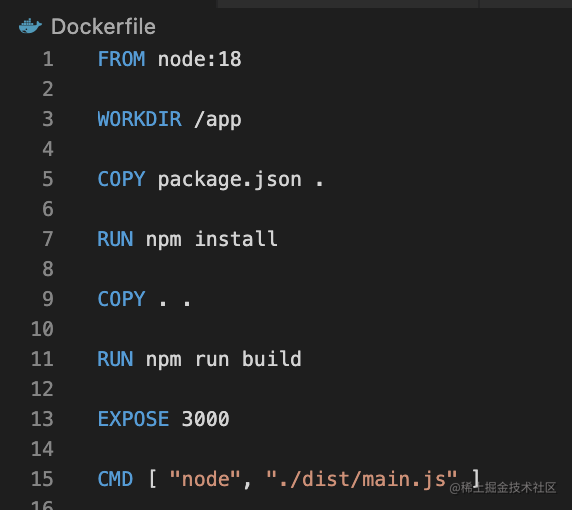
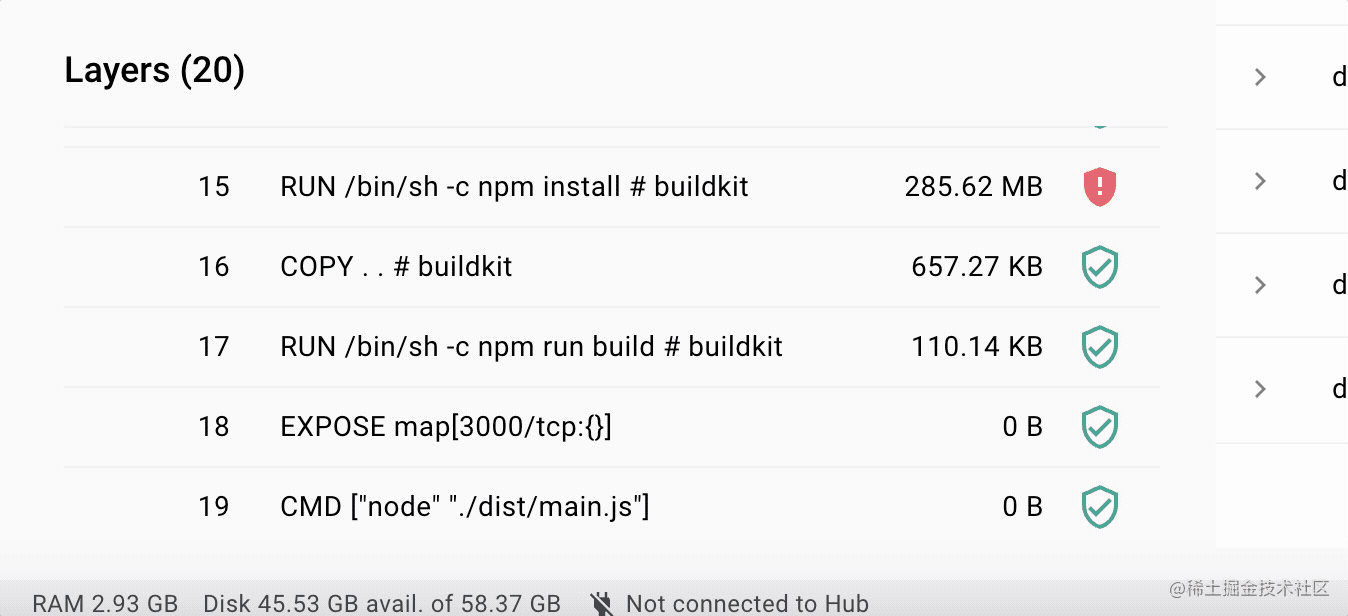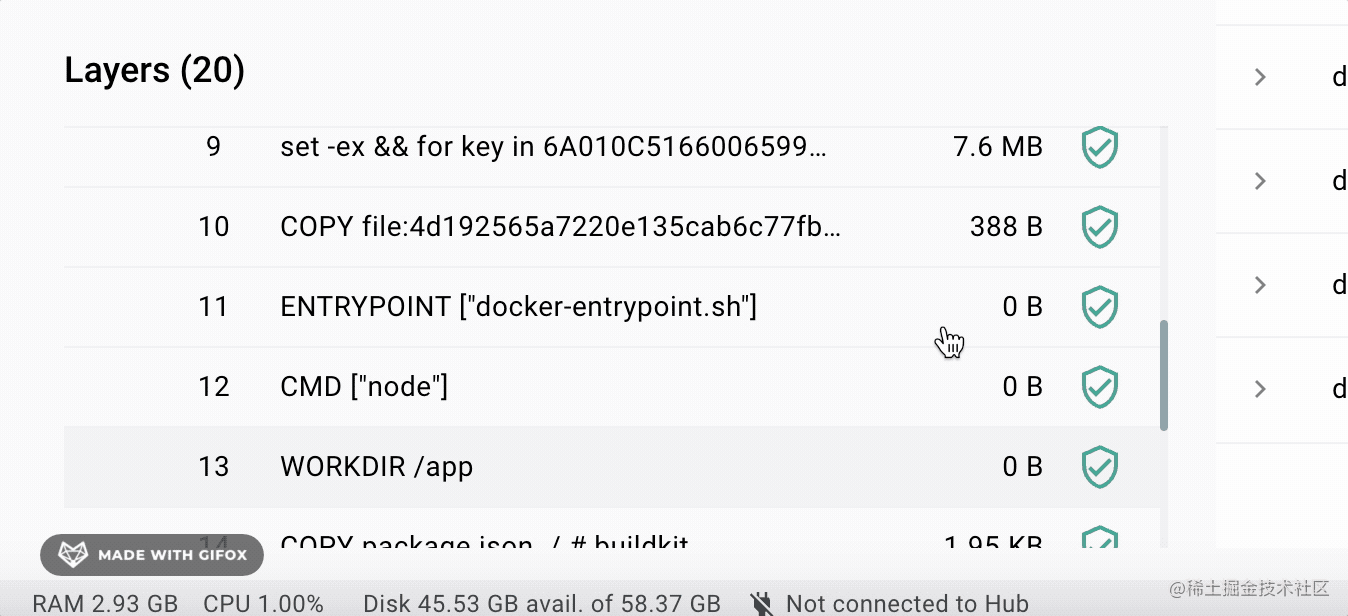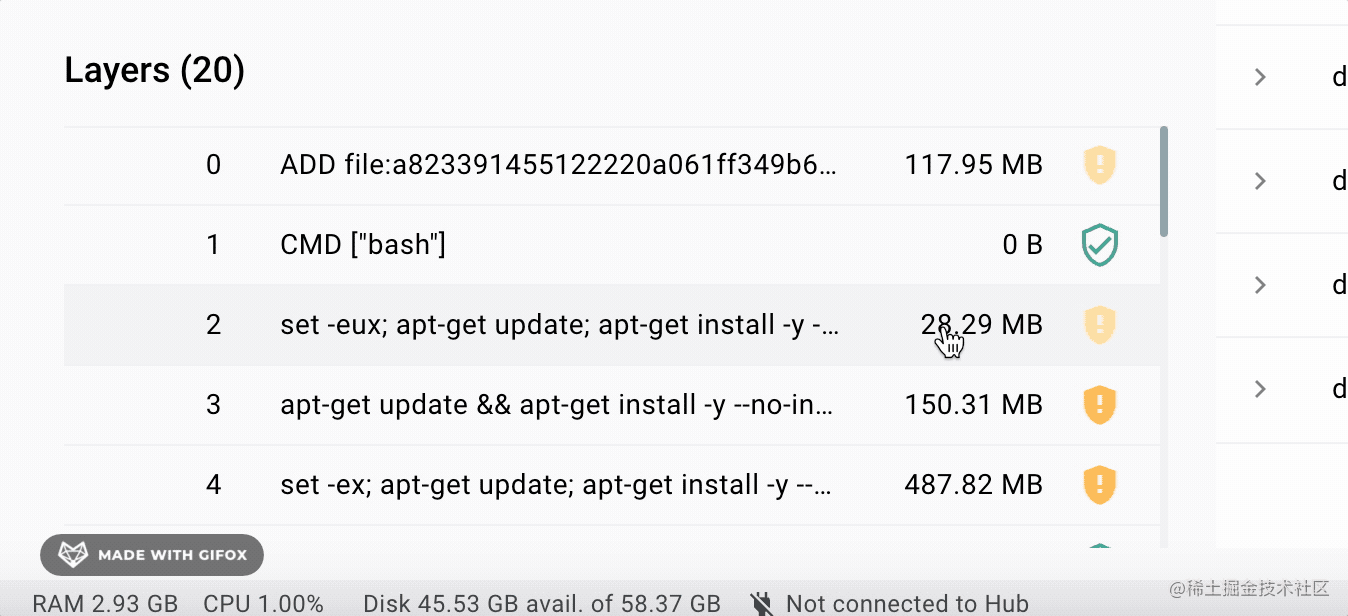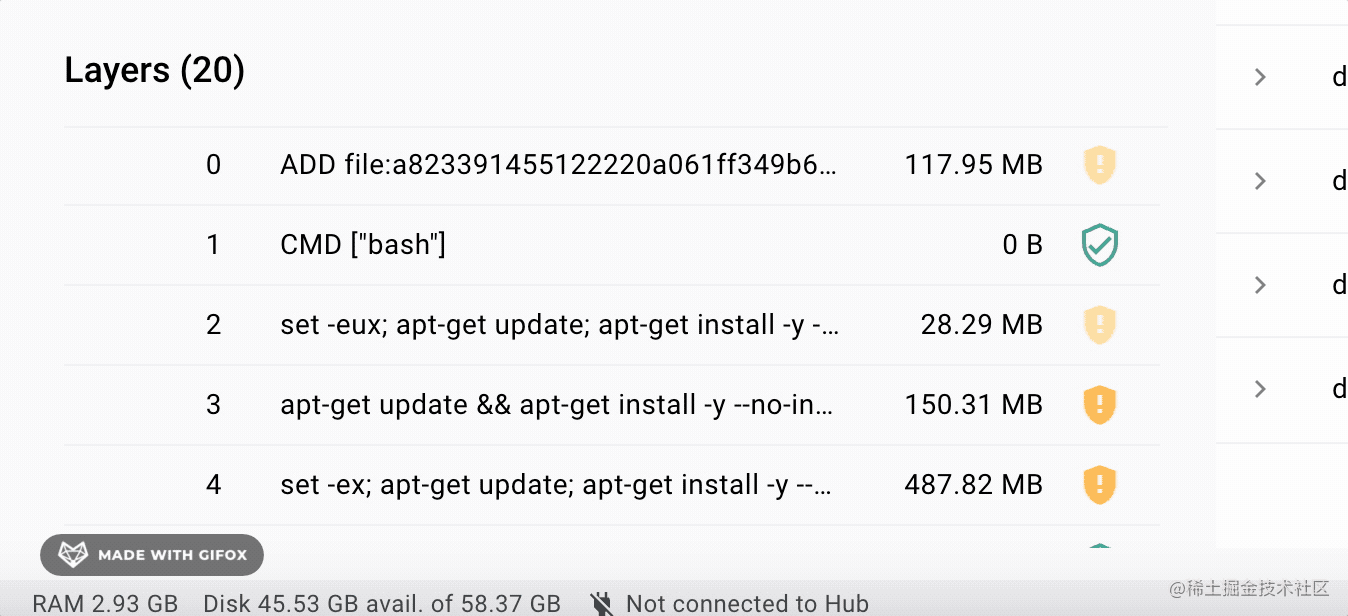
点开 docker 镜像的详情可以看到:
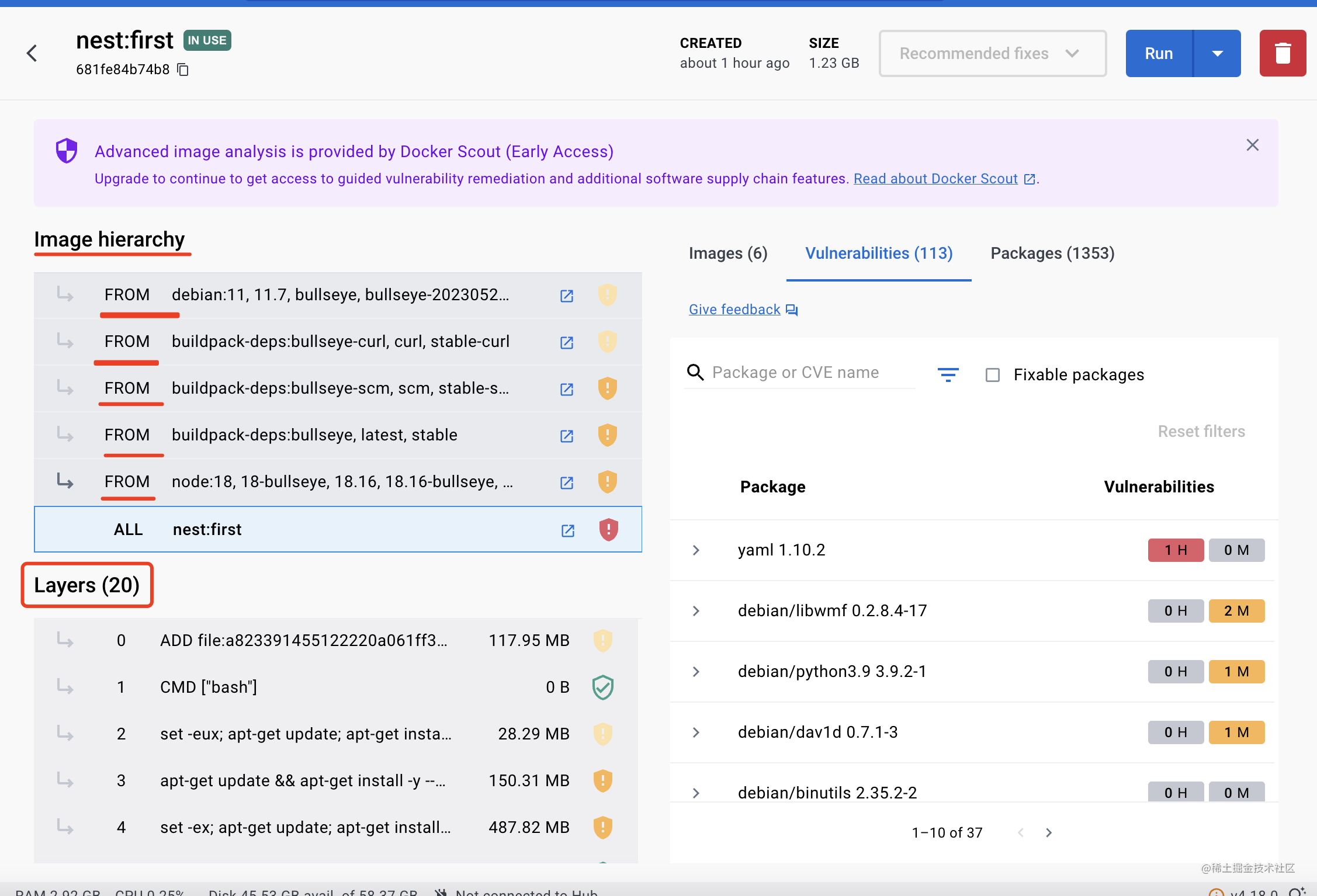
就上面这个 dockerfile,它对应的镜像就有 20 层。
当然,很多都是一层层通过 FROM 继承下来的。
Docker 通过这种分层的镜像存储,极大的减少了文件系统的磁盘占用。
哪里看出来的呢?
比如 nest 的镜像有 1g 多:

但是很多都是它继承的 node 镜像里的,可以看到每一层用了多少存储空间:
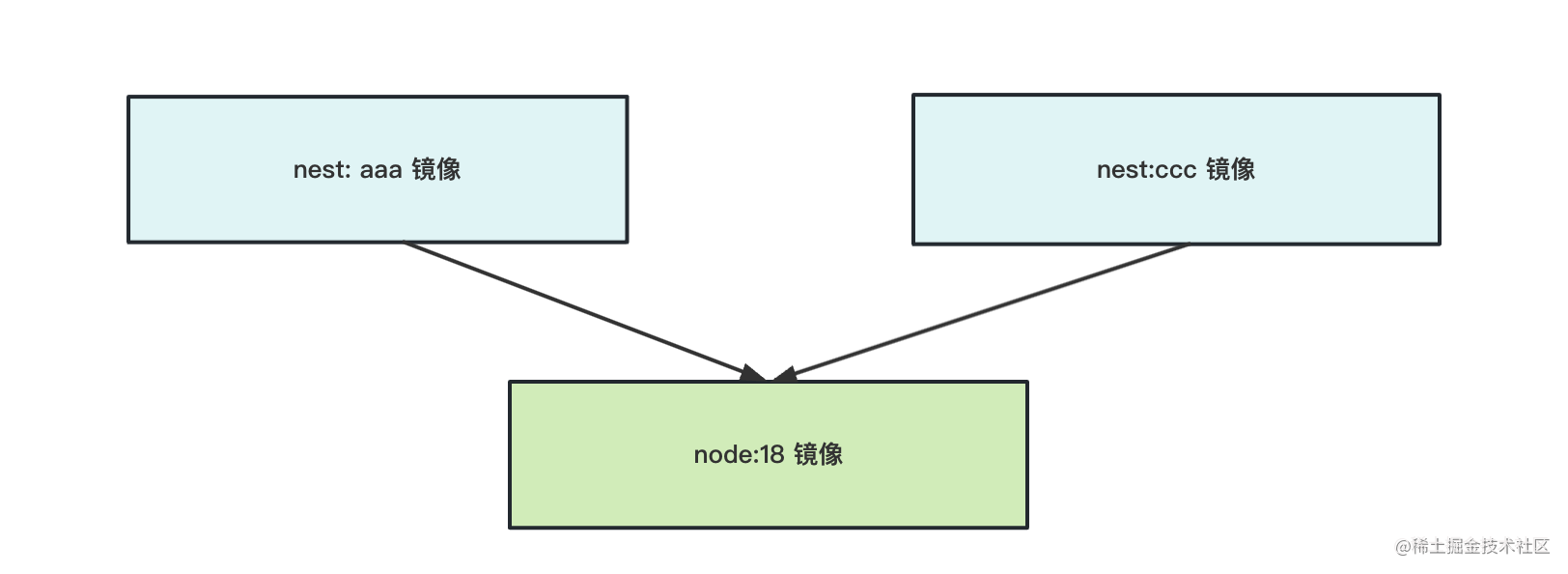
我本地两个 nest 镜像,它们都继承了 node 镜像,这两个合起来有 2g 的存储空间么?
没有,因为下面的镜像层是公用的:
如果有 10 个这种类似的镜像,之前需要 10g。现在呢?可能不到 2g 就够了。
这就是分层存储的魅力。
而且还可以把这些镜像 push 到 registry 镜像仓库,别人拉下来也可以直接用。
但镜像是不可修改的,那为啥我们可以在容器内写文件呢?
因为容器跑起来会给他多加一个可写层,或者叫容器层:
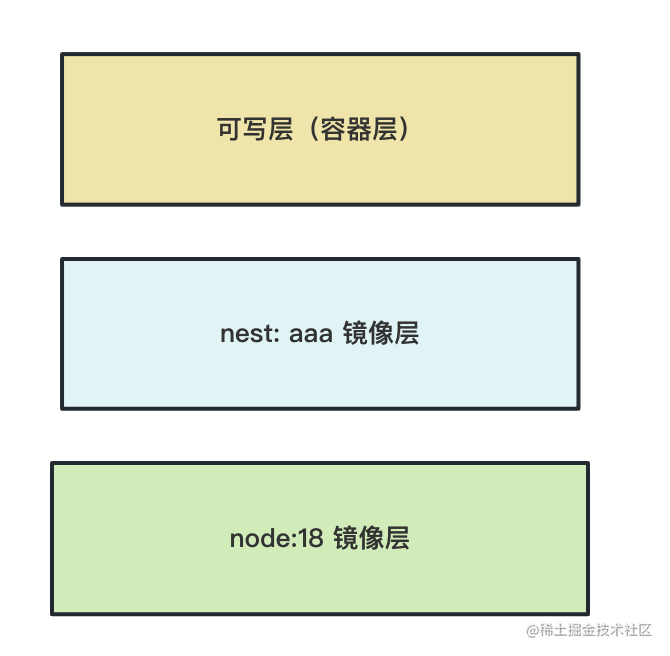
这样容器就能在这里一层写文件了。
当然,再跑一个容器会创建一个新的可写层,另一个容器的可写层的数据就丢了。
所以 Docker 设计了挂载机制,可以挂载数据卷到这个可写层上去。
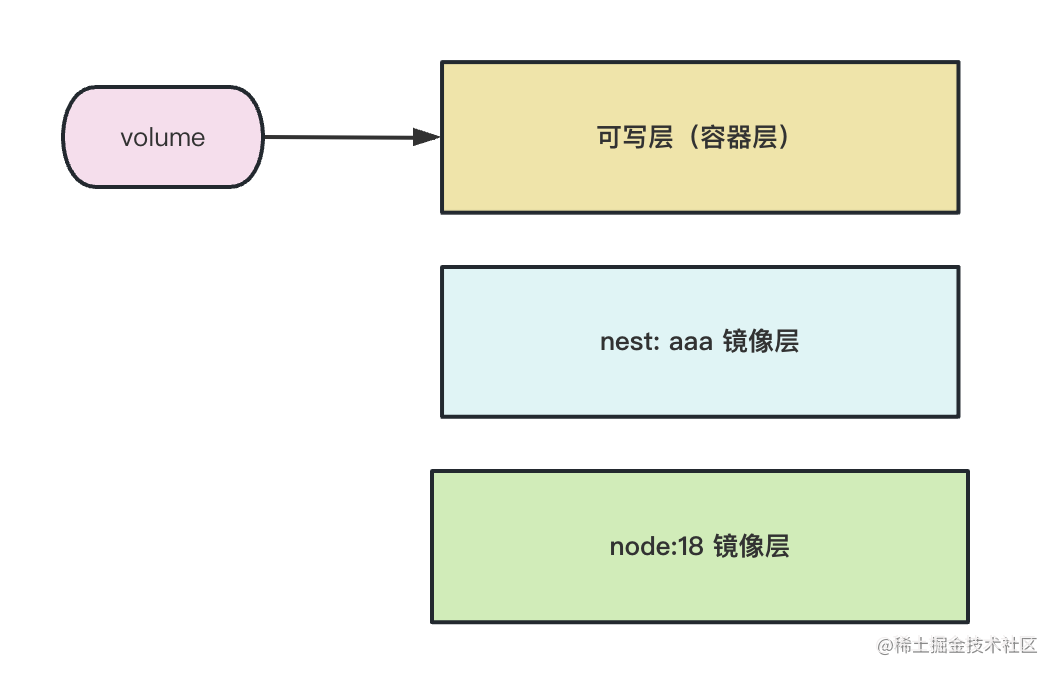
这个数据卷是可以持久化的,再跑个新容器,依然可以把这个 volume 挂上去。
这就是数据卷的作用。
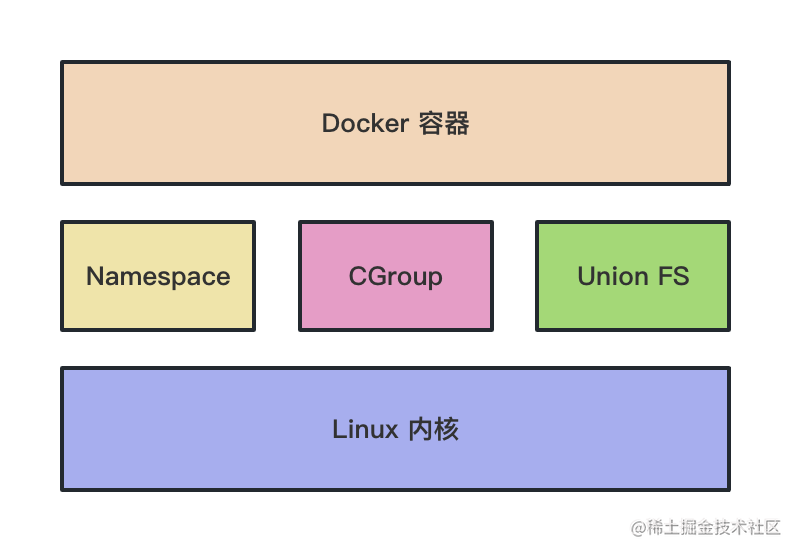
回顾一下 Docker 实现原理的三大基础技术:
- Namespace:实现各种资源的隔离
- Control Group:实现容器进程的资源访问限制
- UnionFS:实现容器文件系统的分层存储,镜像合并
都是缺一不可的。
# 总结
Docker 的实现原理依赖 linux 的 Namespace、Control Group、UnionFS 这三种机制。
Namespace 做资源隔离,Control Group 做容器的资源限制,UnionFS 做文件系统的分层镜像存储、镜像合并。
我们通过 dockerfile 描述镜像构建的过程,每一条指令都是一个镜像层。
镜像通过 docker run 就可以跑起来,对外提供服务,这时会添加一个可写层(容器层)。
挂载一个 volume 数据卷到 Docker 容器,就可以实现数据的持久化。
这就是 Docker 的实现原理。