
 nodejs入门
nodejs入门# 读取环境变量
Node.js 的 process 核心模块提供了 env 属性,该属性承载了在启动进程时设置的所有环境变量。
process.env.NODE_ENV // "development"
在脚本运行之前将其设置为 "production",则可告诉 Node.js 这是生产环境。
# 使用命令行接收参数
获取参数值的方法是使用 Node.js 中内置的 process 对象。
它公开了 argv 属性,该属性是一个包含所有命令行调用参数的数组。
// server.js
process.argv.forEach((val, index) => {
console.log(`${index}: ${val}`)
})
// 在命令行内执行命令:
node server.js one two=three four
// 输出:
0: C:\Program Files\nodejs\node.exe // 第一个参数是 node 命令的完整路径
1: C:\Users\Tina\Desktop\redux-test-app\src\server\server.js // 第二个参数是正被执行的文件的完整路径。
2: one // 所有其他的参数从第三个位置开始。
3: two=three
4: four
2
3
4
5
6
7
8
9
10
11
12
13
也可以通过创建一个排除了前两个参数的新数组来仅获取其他的参数:
const args = process.argv.slice(2)
# 输出到命令行
# 打印
console.log()命令就能简单的将数据输出到命令行。
console.log('输出到了命令行')
# 打印堆栈踪迹
在某些情况下,打印函数的调用堆栈踪迹很有用,可以回答以下问题:如何到达代码的那一部分?
可以使用 console.trace() 实现:
const function2 = () => console.trace()
const function1 = () => function2()
function1()
2
3
这会打印堆栈踪迹。 如果在 Node.js REPL 中尝试此操作,则会打印以下内容:
Trace
at function2 (repl:1:33)
at function1 (repl:1:25)
at repl:1:1
at ContextifyScript.Script.runInThisContext (vm.js:44:33)
at REPLServer.defaultEval (repl.js:239:29)
at bound (domain.js:301:14)
at REPLServer.runBound [as eval] (domain.js:314:12)
at REPLServer.onLine (repl.js:440:10)
at emitOne (events.js:120:20)
at REPLServer.emit (events.js:210:7)
2
3
4
5
6
7
8
9
10
11
# 创建进度条
Progress (opens new window) 是一个很棒的软件包,可在控制台中创建进度条。 使用 npm install progress 进行安装。
以下代码段会创建一个 10 步的进度条,每 100 毫秒完成一步。 当进度条结束时,则清除定时器:
const ProgressBar = require('progress')
const bar = new ProgressBar(':bar', { total: 10 })
const timer = setInterval(() => {
bar.tick()
if (bar.complete) {
clearInterval(timer)
}}, 100)
2
3
4
5
6
7
# 从命令行输出到代码
Node.js 提供了 readline 模块 (opens new window)来执行以下操作:每次一行地从可读流(例如 process.stdin 流,在 Node.js 程序执行期间该流就是终端输入)获取输入。
const readline = require('readline').createInterface({
input: process.stdin,
output: process.stdout
})
// question() 方法会显示第一个参数(即问题),并等待用户的输入。 当按下回车键时,则它会调用回调函数。
readline.question(`你叫什么名字?`, name => {
console.log(`你好 ${name}!`)
readline.close() // 关闭了 readline 接口
})
2
3
4
5
6
7
8
9
10
这段代码会询问用户名,当输入了文本并且用户按下回车键时,则会发送问候语。
最简单的方式是使用 readline-sync 软件包 (opens new window),其在 API 方面非常相似。
Inquirer.js 软件包 (opens new window)则提供了更完整、更抽象的解决方案。
可以使用 npm install inquirer 进行安装,然后复用上面的代码如下:
const inquirer = require('inquirer')
var questions = [
{
type: 'input',
name: 'name',
message: "你叫什么名字?"
}
]
inquirer.prompt(questions).then(answers => {
console.log(`你好 ${answers['name']}!`)
})
2
3
4
5
6
7
8
9
10
11
Inquirer.js 可以执行许多操作,例如询问多项选择、展示单选按钮、确认等。
# 导出和引入
可以通过两种方式进行操作。
第一种方式是将对象赋值给 module.exports(这是模块系统提供的对象),这会使文件只导出该对象:
const car = {
brand: 'Ford', model: 'Fiesta'
}
module.exports = car
//在另一个文件中
const car = require('./car')
2
3
4
5
6
7
第二种方式是将要导出的对象添加为 exports 的属性。这种方式可以导出多个对象、函数或数据:
const car = {
brand: 'Ford',
model: 'Fiesta'
}
exports.car = car
//在另一个文件中
const items = require('./items')
items.car
2
3
4
5
6
7
8
9
module.exports和export之间有什么区别?前者公开了它指向的对象。 后者公开了它指向的对象的属性。
# package.json
package.json 文件是项目的清单。 它可以做很多完全互不相关的事情。 例如,它是用于工具的配置中心。 它也是 npm 和 yarn 存储所有已安装软件包的名称和版本的地方。
一下是一个较全面的示例,该示例是从 Vue.js 应用程序示例中提取的:
{
"name": "test-project",
"version": "1.0.0",
"description": "A Vue.js project",
"main": "src/main.js",
"private": true,
"scripts": {
"dev": "webpack-dev-server --inline --progress --config build/webpack.dev.conf.js",
"start": "npm run dev",
"unit": "jest --config test/unit/jest.conf.js --coverage",
"test": "npm run unit",
"lint": "eslint --ext .js,.vue src test/unit",
"build": "node build/build.js"
},
"dependencies": {
"vue": "^2.5.2"
},
"devDependencies": {
"babel-core": "^6.22.1",
"babel-eslint": "^8.2.1",
"chalk": "^2.0.1",
"css-loader": "^0.28.0",
"eslint": "^4.15.0",
"eslint-plugin-import": "^2.7.0",
"eslint-plugin-vue": "^4.0.0",
"vue-loader": "^13.3.0",
"webpack": "^3.6.0",
"webpack-bundle-analyzer": "^2.9.0",
},
"engines": {
"node": ">= 6.0.0",
"npm": ">= 3.0.0"
},
"browserslist": ["> 1%", "last 2 versions", "not ie <= 8"]
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
这里有很多东西:
version表明了当前的版本。name设置了应用程序/软件包的名称。description是应用程序/软件包的简短描述。main设置了应用程序的入口点。private如果设置为true,则可以防止应用程序/软件包被意外地发布到npm。scripts定义了一组可以运行的 node 脚本。dependencies设置了作为依赖安装的npm软件包的列表。devDependencies设置了作为开发依赖安装的npm软件包的列表。engines设置了此软件包/应用程序在哪个版本的 Node.js 上运行。browserslist用于告知要支持哪些浏览器(及其版本)。
提示
更多属性详解可以参考:技术-->技术文档--> npm packageJson属性详解
# package-lock.json
该文件旨在跟踪被安装的每个软件包的确切版本,以便产品可以以相同的方式被 100% 复制(即使软件包的维护者更新了软件包)。
package-lock.json 会固化当前安装的每个软件包的版本,当运行 npm install时,npm 会使用这些确切的版本。
当运行 npm update 时,package-lock.json 文件中的依赖的版本会被更新。
# npm 语义版本控制
语义版本控制的概念很简单:所有的版本都有 3 个数字:x.y.z。
- 第一个数字是主版本。
- 第二个数字是次版本。
- 第三个数字是补丁版本。
当发布新的版本时,不仅仅是随心所欲地增加数字,还要遵循以下规则:
- 当进行不兼容的 API 更改时,则升级主版本。
- 当以向后兼容的方式添加功能时,则升级次版本。
- 当进行向后兼容的缺陷修复时,则升级补丁版本。
该约定在所有编程语言中均被采用,每个 npm 软件包都必须遵守该约定,这一点非常重要,因为整个系统都依赖于此。
npm 设置了一些规则,可用于在 package.json 文件中选择要将软件包更新到的版本(当运行 npm update 时)。
规则使用了这些符号:
^~>>=<<==-||
这些规则的详情如下:
^: 只会执行不更改最左边非零数字的更新。 如果写入的是^0.13.0,则当运行npm update时,可以更新到0.13.1、0.13.2等,但不能更新到0.14.0或更高版本。 如果写入的是^1.13.0,则当运行npm update时,可以更新到1.13.1、1.14.0等,但不能更新到2.0.0或更高版本。~: 如果写入的是〜0.13.0,则当运行npm update时,会更新到补丁版本:即0.13.1可以,但0.14.0不可以。>: 接受高于指定版本的任何版本。>=: 接受等于或高于指定版本的任何版本。<=: 接受等于或低于指定版本的任何版本。<: 接受低于指定版本的任何版本。=: 接受确切的版本。-: 接受一定范围的版本。例如:2.1.0 - 2.6.2。||: 组合集合。例如< 2.1 || > 2.6。
可以合并其中的一些符号,例如 1.0.0 || >=1.1.0 <1.2.0,即使用 1.0.0 或从 1.1.0 开始但低于 1.2.0 的版本。
还有其他的规则:
- 无符号: 仅接受指定的特定版本(例如
1.2.1)。 latest: 使用可用的最新版本。
# 包运行器npx
如果不想安装 npm,则可以安装 npx 为独立的软件包 (opens new window)。
npx 可以运行使用 Node.js 构建并通过 npm 仓库发布的代码。
# 使用不同的 Node.js 版本运行代码
使用 @ 指定版本,并将其与 node npm 软件包 (opens new window) 结合使用:
npx node@10 -v #v10.18.1
npx node@12 -v #v12.14.1
2
这有助于避免使用 nvm 之类的工具或其他 Node.js 版本管理工具。
# 直接从 URL 运行任意代码片段
npx 并不限制使用 npm 仓库上发布的软件包。
可以运行位于 GitHub gist 中的代码,例如:
npx https://gist.github.com/zkat/4bc19503fe9e9309e2bfaa2c58074d32
当然,当运行不受控制的代码时,需要格外小心,因为强大的功能带来了巨大的责任。
# 事件循环
Node.js JavaScript 代码运行在单个线程上。 每次只处理一件事。
这个限制实际上非常有用,因为它大大简化了编程方式,而不必担心并发问题。
调用堆栈是一个 LIFO 队列(后进先出)。
事件循环不断地检查调用堆栈,以查看是否需要运行任何函数。
当执行时,它会将找到的所有函数调用添加到调用堆栈中,并按顺序执行每个函数。
# 消息队列
const bar = () => console.log('bar')
const baz = () => console.log('baz')
const foo = () => { console.log('foo') setTimeout(bar, 0) baz()}
foo()
2
3
4
该代码会打印:
foo
baz
bar
2
3
函数的执行顺序:
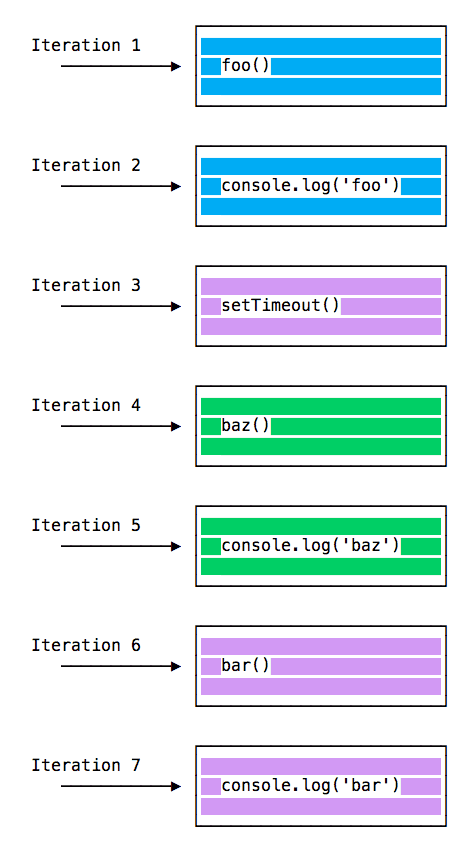
# ES6 作业队列
ECMAScript 2015 引入了作业队列的概念,Promise 使用了该队列(也在 ES6/ES2015 中引入)。 这种方式会尽快地执行异步函数的结果,而不是放在调用堆栈的末尾。
在当前函数结束之前 resolve 的 Promise 会在当前函数之后被立即执行。
有个游乐园中过山车的比喻很好:消息队列将你排在队列的后面(在所有其他人的后面),你不得不等待你的回合,而工作队列则是快速通道票,这样你就可以在完成上一次乘车后立即乘坐另一趟车。
示例:
const bar = () => console.log('bar')
const baz = () => console.log('baz')
const foo = () => {
console.log('foo')
setTimeout(bar, 0)
new Promise((resolve, reject) =>
resolve('应该在 baz 之后、bar 之前')
).then(resolve => console.log(resolve))
baz()
}
foo()
2
3
4
5
6
7
8
9
10
11
这会打印:
foo
baz
应该在 baz 之后、bar 之前
bar
2
3
4
这是 Promise(以及基于 promise 构建的 async/await)与通过 setTimeout() 或其他平台 API 的普通的旧异步函数之间的巨大区别。
# process.nextTick()
每当事件循环进行一次完整的行程时,我们都将其称为一个滴答。
当将一个函数传给 process.nextTick() 时,则指示引擎在当前操作结束(在下一个事件循环滴答开始之前)时调用此函数:
process.nextTick(() => {
//做些事情
})
2
3
事件循环正在忙于处理当前的函数代码。
当该操作结束时,JS 引擎会运行在该操作期间传给 nextTick 调用的所有函数。
调用 setTimeout(() => {}, 0) 会在下一个滴答结束时执行该函数,比使用 nextTick()(其会优先执行该调用并在下一个滴答开始之前执行该函数)晚得多。
当要确保在下一个事件循环迭代中代码已被执行,则使用 nextTick()。
# 事件触发器
在后端,Node.js 也提供了使用 events 模块 (opens new window)构建类似系统的选项。
使用以下代码进行初始化:
const EventEmitter = require('events')
const eventEmitter = new EventEmitter()
2
该对象公开了 on 和 emit 方法。
emit用于触发事件。on用于添加回调函数(会在事件被触发时执行)。
例如,创建 start 事件,并提供一个示例,通过记录到控制台进行交互:
eventEmitter.on('start', () => {
console.log('开始')
})
2
3
EventEmitter 对象还公开了其他几个与事件进行交互的方法,例如:
once(): 添加单次监听器。removeListener()/off(): 从事件中移除事件监听器。removeAllListeners(): 移除事件的所有监听器。
# 搭建HTTP服务器
这是一个简单的 HTTP web 服务器的示例:
const http = require('http')
const port = 3000
const server = http.createServer((req, res) => {
res.statusCode = 200
res.setHeader('Content-Type', 'text/plain')
res.end('你好世界\n')
})
server.listen(port, () => {
console.log(`服务器运行在 http://${hostname}:${port}/`)
})
2
3
4
5
6
7
8
9
10
# 发送HTTP请求
# 执行GET请求
const https = require('https')
const options = {
hostname: 'nodejs.cn',
port: 443,
path: '/todos',
method: 'GET'
}
const req = https.request(options, res => {
console.log(`状态码: ${res.statusCode}`)
res.on('data', d => {
process.stdout.write(d)
})
})
req.on('error', error => {
console.error(error)
})
req.end()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 执行POST请求
const https = require('https')
const data = JSON.stringify({
todo: '做点事情'
})
const options = {
hostname: 'nodejs.cn',
port: 443,
path: '/todos',
method: 'POST',
headers: {
'Content-Type': 'application/json',
'Content-Length': data.length
}
}
const req = https.request(options, res => {
console.log(`状态码: ${res.statusCode}`)
res.on('data', d => {
process.stdout.write(d)
})
})
req.on('error', error => {
console.error(error)
})
req.write(data)
req.end(
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
# PUT 和 DELETE
PUT 和 DELETE 请求使用相同的 POST 请求格式,只需更改 options.method 的值即可。
# Axios库
使用 Node.js 执行 HTTP 请求的最简单的方式是使用 Axios 库 (opens new window)。
上面的 post 请求可以写成:
const axios = require('axios')
axios
.post('http://nodejs.cn/todos', {
todo: '做点事情'
})
.then(res => {
console.log(`状态码: ${res.statusCode}`)
console.log(res)
})
.catch(error => {
console.error(error)
})
2
3
4
5
6
7
8
9
10
11
12
13
# 获取HTTP请求的正文数据
如果使用的是 Express,则非常简单:使用 body-parser Node.js 模块。
例如,获取此请求的正文:
const axios = require('axios')
axios.post('http://nodejs.cn/todos', { todo: '做点事情'})
2
这是对应的服务器端代码:
const express = require('express')
const app = express()
app.use(
express.urlencoded({
extended: true
})
)
app.use(express.json())
app.post('/todos', (req, res) => {
console.log(req.body.todo)
})
2
3
4
5
6
7
8
9
10
11
如果不使用 Express 并想在普通的 Node.js 中执行此操作,则需要做多一点的工作,因为 Express 抽象了很多工作。
要理解的关键是,当使用 http.createServer() 初始化 HTTP 服务器时,服务器会在获得所有 HTTP 请求头(而不是请求正文时)时调用回调。
# 获取文件属性
使用 fs 模块提供的 stat() 方法。
调用时传入文件的路径,一旦 Node.js 获得文件的详细信息,则会调用传入的回调函数,并带上两个参数:错误消息和文件属性:
const fs = require('fs')
fs.stat('/Users/joe/test.txt', (err, stats) => {
if (err) {
console.error(err)
return
}
//可以访问 `stats` 中的文件属性
stats.isFile() //true
stats.isDirectory() //false
stats.isSymbolicLink() //false
stats.size //1024000 //= 1MB
})
2
3
4
5
6
7
8
9
10
11
12
Node.js 也提供了同步的方法,该方法会阻塞线程,直到文件属性准备就绪为止:
const fs = require('fs')
try {
const stats = fs.statSync('/Users/joe/test.txt')
} catch (err) {
console.error(err)
}
2
3
4
5
6
文件的信息包含在属性变量中。 可以通过属性提取哪些信息?
很多,包括:
- 使用
stats.isFile()和stats.isDirectory()判断文件是否目录或文件。 - 使用
stats.isSymbolicLink()判断文件是否符号链接。 - 使用
stats.size获取文件的大小(以字节为单位)。
还有其他一些高级的方法,但是在日常编程中会使用的大部分是这些。
# 获取文件路径
系统中的每个文件都有路径。
在 Linux 和 macOS 上,路径可能类似于:
/users/joe/file.txt
在 Windows 上则有所不同,具有类似以下的结构:
C:\users\joe\file.txt
当在应用程序中使用路径时需要注意,因为必须考虑到这种差异。
可以使用以下方式将此模块引入到文件中:
const path = require('path')
# 从路径中获取信息
给定一个路径,可以使用以下方法从其中提取信息:
dirname: 获取文件的父文件夹。basename: 获取文件名部分。extname: 获取文件的扩展名。
例如:
const notes = '/users/joe/notes.txt'
path.dirname(notes) // /users/joepath.basename(notes) // notes.txtpath.extname(notes) // .txt
2
可以通过为 basename 指定第二个参数来获取不带扩展名的文件名:
path.basename(notes, path.extname(notes)) //notes
# 使用路径
可以使用 path.join() 连接路径的两个或多个片段:
const name = 'joe'
path.join('/', 'users', name, 'notes.txt') //'/users/joe/notes.txt'
2
可以使用 path.resolve() 获得相对路径的绝对路径计算:
path.resolve('joe.txt') //'/Users/joe/joe.txt' 如果从主文件夹运行。
在此示例中,Node.js 只是简单地将 /joe.txt 附加到当前工作目录。 如果指定第二个文件夹参数,则 resolve 会使用第一个作为第二个的基础:
path.resolve('tmp', 'joe.txt') //'/Users/joe/tmp/joe.txt' 如果从主文件夹运行。
如果第一个参数以斜杠开头,则表示它是绝对路径:
path.resolve('/etc', 'joe.txt') //'/etc/joe.txt'
第一个参数为__dirname,表示当前文件所在目录(即上一级)
// myApp/server.js
path.resolve(__dirname, 'src') //'/myApp/src'
2
path.normalize() 是另一个有用的函数,当包含诸如 .、.. 或双斜杠之类的相对说明符时,其会尝试计算实际的路径:
path.normalize('/users/joe/..//test.txt') //'/users/test.txt'
解析和规范化都不会检查路径是否存在。 其只是根据获得的信息来计算路径。
# 读取文件
最简单的方式是使用 fs.readFile() 方法,向其传入文件路径、编码、以及会带上文件数据(以及错误)进行调用的回调函数:
const fs = require('fs')
fs.readFile('/Users/joe/test.txt', 'utf8' , (err, data) => {
if (err) {
console.error(err)
return
}
console.log(data)
})
2
3
4
5
6
7
8
另外,也可以使用同步的版本 fs.readFileSync():
const fs = require('fs')
try {
const data = fs.readFileSync('/Users/joe/test.txt', 'utf8')
console.log(data)
} catch (err) {
console.error(err)
}
2
3
4
5
6
7
fs.readFile() 和 fs.readFileSync() 都会在返回数据之前将文件的全部内容读取到内存中。
这意味着大文件会对内存的消耗和程序执行的速度产生重大的影响。
在这种情况下,更好的选择是使用流来读取文件的内容。
# 写入文件
在 Node.js 中写入文件最简单的方式是使用 fs.writeFile() API。
const fs = require('fs')
const content = '一些内容'
fs.writeFile('/Users/joe/test.txt', content, err => {
if (err) {
console.error(err)
return
}
//文件写入成功。
})
2
3
4
5
6
7
8
9
10
11
另外,也可以使用同步的版本 fs.writeFileSync():
const fs = require('fs')
const content = '一些内容'
try {
const data = fs.writeFileSync('/Users/joe/test.txt', content)
//文件写入成功。
} catch (err) {
console.error(err)
}
2
3
4
5
6
7
8
# 文件系统模块
fs 模块提供了许多非常实用的函数来访问文件系统并与文件系统进行交互。
无需安装。 作为 Node.js 核心的组成部分,可以通过简单地引用来使用它:
const fs = require('fs')
一旦这样做,就可以访问其所有的方法,包括:
fs.access(): 检查文件是否存在,以及 Node.js 是否有权限访问。fs.appendFile(): 追加数据到文件。如果文件不存在,则创建文件。fs.chmod(): 更改文件(通过传入的文件名指定)的权限。相关方法:fs.lchmod()、fs.fchmod()。fs.chown(): 更改文件(通过传入的文件名指定)的所有者和群组。相关方法:fs.fchown()、fs.lchown()。fs.close(): 关闭文件描述符。fs.copyFile(): 拷贝文件。fs.createReadStream(): 创建可读的文件流。fs.createWriteStream(): 创建可写的文件流。fs.link(): 新建指向文件的硬链接。fs.mkdir(): 新建文件夹。fs.mkdtemp(): 创建临时目录。fs.open(): 设置文件模式。fs.readdir(): 读取目录的内容。fs.readFile(): 读取文件的内容。相关方法:fs.read()。fs.readlink(): 读取符号链接的值。fs.realpath(): 将相对的文件路径指针(.、..)解析为完整的路径。fs.rename(): 重命名文件或文件夹。fs.rmdir(): 删除文件夹。fs.stat(): 返回文件(通过传入的文件名指定)的状态。相关方法:fs.fstat()、fs.lstat()。fs.symlink(): 新建文件的符号链接。fs.truncate(): 将传递的文件名标识的文件截断为指定的长度。相关方法:fs.ftruncate()。fs.unlink(): 删除文件或符号链接。fs.unwatchFile(): 停止监视文件上的更改。fs.utimes(): 更改文件(通过传入的文件名指定)的时间戳。相关方法:fs.futimes()。fs.watchFile(): 开始监视文件上的更改。相关方法:fs.watch()。fs.writeFile(): 将数据写入文件。相关方法:fs.write()。
关于 fs 模块的特殊之处是,所有的方法默认情况下都是异步的,但是通过在前面加上 Sync 也可以同步地工作。